

Hey there, reliability champions! 👋
Your incident management strategy can make or break your organization's reliability goals. As SRE and DevOps teams manages increasingly complex systems, effective incident management becomes crucial for maintaining service reliability and customer satisfaction. You need a structured approach that combines monitoring, automation, and proven response strategies to handle incidents efficiently.
This post build upon the previous weeks, where we went through fundamentals of SRE, Monitoring and SLOs. Make sure to check them out, starting here:

Throughout this post, I hope to share essential site reliability engineering practices that can transform your incident management process.
1. Introduction to Incident Management
Let's start off by looking into how implementing proper Site Reliability Engineering practices can transform traditional incident response into a well-oiled machine that keeps your systems running smoothly.
Definition and importance
Having a proper Incident Management policy ensures a systematic approach to handling service disruptions through engineering-driven solutions. It's not just about putting out fires – it's about building a robust framework that combines software engineering principles with operations expertise in order to maintain system reliability. Think of it as your organization's immune system, constantly monitoring, responding, and adapting to keep your services healthy.
Key principles of SRE incident management
At its core, SRE incident management revolves around what we call the "3Cs":
- Coordinate: By establishing clear command structures and roles
- Communicate: By maintaining a transparent information flow
- Control: By executing systematic response procedures
It's important to have clearly defined roles within a incident response team. Here's an example with a common set of roles that are used amongst incident management teams:
- Incident Commander (IC): Owns the incident, and is the primary point of contact and source of truth about your incident. They see the big picture, manage all the moving pieces, know what’s been tried and what’s still on the radar, and plan for and manage next steps.
- Operations Lead (OL): Drives the technical investigation and resolution.
- Communications Lead (CL): Manages updates to customers, status pages, stakeholders, documentation, and so on...
With smaller teams, a single engineer may fill more than one role during an incident. However, it is best for the engineers to focus on fixing the incident, and have other team members, or a specialized communications team, deal with the updates to stakeholders, customers, status pages, and so on.
How it differs from traditional incident management
Traditional incident management often relies on reactive approaches and hero culture.
SRE takes a different path: You're implementing a data-driven approach that emphasizes on measuring everything from application-specific metrics, to service level objectives (SLOs) and error budgets. These tools help with clearly measuring the severity of an incident, and guide the appropriate actions necessary to fix it. Last but not least, instead of pointing fingers when things go wrong, you're also fostering a blameless culture that focuses on learning and continuous improvement.
The SRE approach transforms your incident management by:
- Embracing automation to reduce toil and human error
- Using living documentation that evolves with each incident
- Establishing well-defined processes for escalation and handover
- Focusing on systematic improvements rather than quick fixes
- Note that quick fixes are more than welcome to quickly restore customer happiness and your systems' health. However, it should only be used as a temporary workaround for that incident.
Your incident management becomes more structured with SRE principles, as you're treating operations as a software problem. This means writing code to automate responses, creating reproducible processes, and continuously improving your system's reliability through data-driven decisions.
2. The Incident Management Lifecycle
Let's dive into an incident management's lifecycle. Understanding each phase helps you build a more resilient system and respond effectively when issues arise.
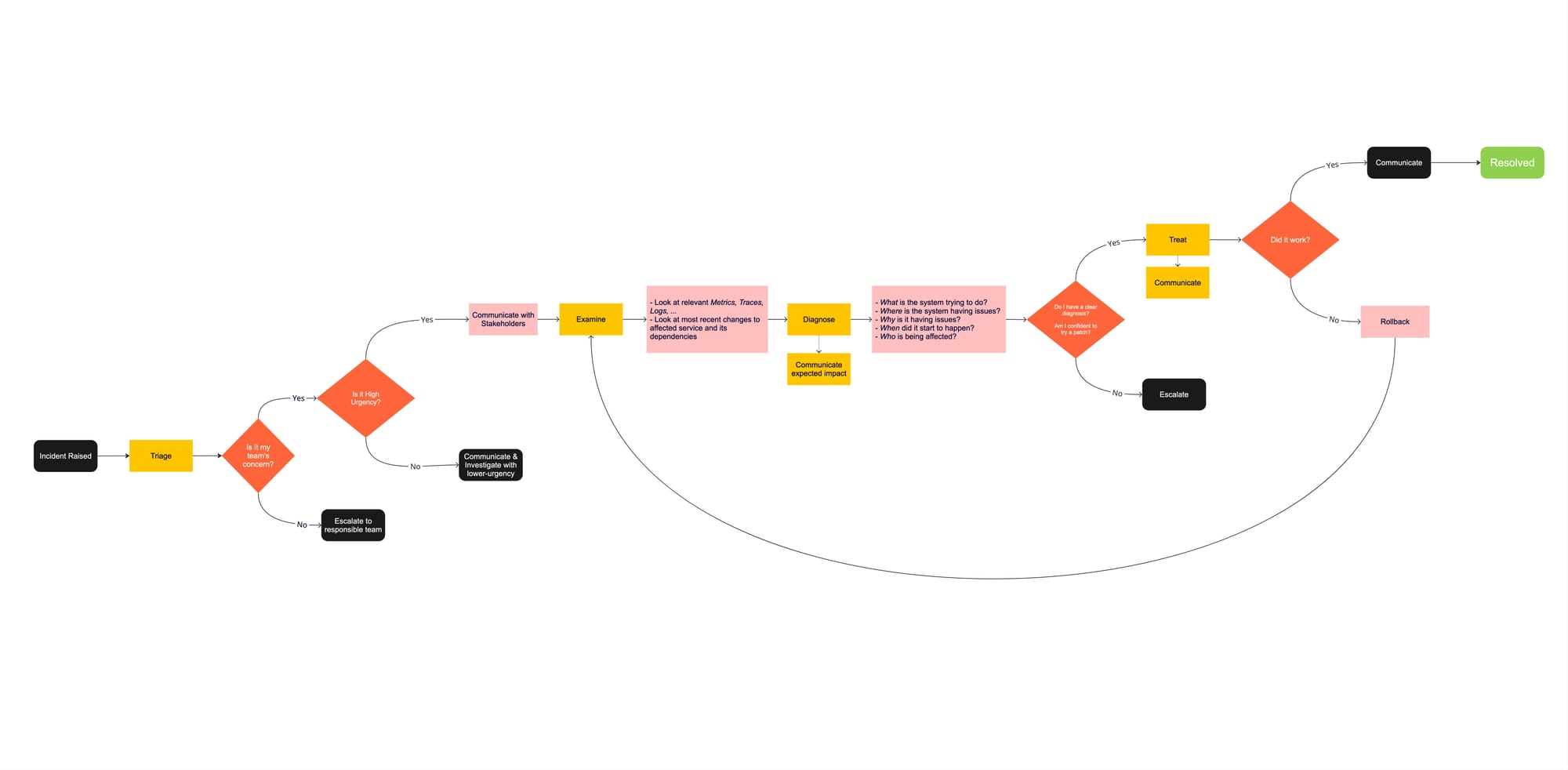
Incident detection and alerting
Your first line of defense is a robust monitoring system. Implement monitoring that focuses on symptoms rather than causes - this means tracking user-facing functionality rather than just internal metrics. Set up alerts based on Service Level Objectives (SLOs) to ensure you're notified of real issues that matter to your customers.
We've covered both of these topics in our previous Week 2 and Week 3 posts. Make sure to check them out here:


Triage and initial response
When an alert fires, quick assessment is crucial. Remember this golden rule: declare incidents early rather than late. It's better to spin up your incident management framework and find a simple fix than to delay and watch a small problem snowball into a crisis – long-lived bugs can be the worst!
Your initial response must follow these key steps:
- Assess severity and impact
- Mobilize appropriate team members, filling every required role
- Begin initial communication
- Start diagnosing issue in-depth
Investigation and diagnosis
During investigation, your operations team should be the only group modifying the system. The incident commander maintains high-level state while the ops team digs into the technical details.
Keep these investigation best practices in mind:
- Document all debugging steps in real-time
- Focus on immediate mitigation first
- Preserve evidence for root cause analysis and reproducibility (e.g. making a change to a database column as a fix? take note of its original value first)
- Consider alternative approaches regularly
Resolution and recovery
Resolution isn't just about fixing the immediate problem - it's about ensuring your system returns to a healthy state. Your ops team implements fixes while the incident commander coordinates with other teams to verify the solution's effectiveness.
While there is no single step-by-step guide to follow in order to find and fix the underlying issue(s) causing an incident, there are some tips I can share that should help you have a clearer path on recovering your system to a healthy state – and bring back your customers' happiness:
- Look for answers to the following questions (The 5 Ws):
- What is your system trying to do?
- This should help you understand what is the overall impact of the incident you're handling, and give you a starting point as to where to look for the underlying issue affecting your system(s).
- e.g My system is trying process and complete new users signups
- Where is your system having issues?
- By looking into where your system is failing, you can start isolating the issue.
- e.g. The auth service is failing to execute a
INSERT INTO users ...SQL query to its database
- Why is it having issues?
- You must understand why your system is misbehaving in order to apply the proper remediation.
- e.g. Errors from the database logs indicates a constraint violation, trying to write
nullvalues to anot nullcolumn.
- When did it start to happen?
- Knowing when an issue began can be really helpful in understanding its overall impact, and can help you associate changes to your system to new errors.
- e.g. First error happened 25 minutes ago
- Who is being affected?
- I can't count how many times I've been paged during my on-call shifts only to find out it was a single user messing with our APIs. Understanding who is being affected during an incident greatly helps with defining its severity level.
- e.g. Every user who attempts to signup
- What is your system trying to do?
Postmortem and learning
Here's where SRE incident management truly shines. After resolving an incident, you should conduct a thorough postmortem analysis in a blameless environment. Document what happened, but focus on the circumstances that contributed to the incident rather than individual actions.
Your postmortem should capture:
- Timeline of events and actions taken
- Overall impact
- Root cause analysis findings
- What worked well in the response
- Areas for improvement
- Action items to prevent recurrence
The Watermelon Effect
You may find during an incident that your monitoring solutions are not properly reflecting an existing impact to your customers, and that your SLOs, Alerts, and Dashboards are all green. This is called the "Watermelon Effect", where from the outside everything looks green, and only when taking a deeper look you'll find red, indicating issues with your system.
To effectively combat the "watermelon effect", you may conduct regular testing of your monitoring coverage. Chaos engineering can help identify blind spots, and we'll cover this topic in future posts.
Additionally, maintain a healthy skepticism of "all green" dashboards by periodically validating your SLO definitions and alert thresholds against actual customer impact. Consider implementing inverse metrics – tracking not just system success but explicit failure modes – and ensure your monitoring stack includes business metrics alongside technical indicators. Regularly review and update these measures as your system evolves and new failure modes emerge.
Remember, effective incident management isn't about preventing all incidents - it's about building a framework that helps you respond efficiently and learn continuously. Each phase of the lifecycle contributes to this goal, from early detection through careful postmortem analysis.
3. Building an Effective Incident Response Team
Now let's explore how you can build and nurture an effective incident response team that keeps your systems running smoothly.
The evolution of an Incident Response Team
Crafting a mature team for handling incidents is an iterative process. Your team most likely fits under one of the following Maturity Levels:
| Maturity Level | Description | Best for |
|---|---|---|
| Sink or Swim | Engineers figure everything out alone without guidance or framework. Low effort but not inclusive nor scalable. | Early stages of a company, with one or few engineers managing the the system(s) reliability |
| Self-study curriculum | Provides checklists and materials for self-guided learning, but lacks support channels. | When engineering and SRE teams start to grow with new hires |
| Buddy System | One-on-one mentoring and shadowing with experienced team members. | Teams with few engineers and systems to manage |
| Ad-hoc Classes | Live, informal training sessions or whiteboard discussions led by team members as needed. | Organizations with 10-50 engineers needing flexible training that can adapt to rapid changes in technology and architecture |
| Systematic Training Program | Formal, structured training with cohorts, curated curriculum, and in-person sessions. | Large organizations (50+ engineers) requiring consistent, scalable training across multiple teams and locations |
On-call rotations and schedules
Creating sustainable on-call schedules is crucial for maintaining team health and effectiveness. Here's a breakdown of common rotation strategies:
| Rotation Type | Description | Best For |
|---|---|---|
| Follow-the-sun | Teams in different time zones handle their business hours | Global organizations |
| Round Robin | Distributes alerts among multiple responders | High-volume environments |
| Primary/Secondary | Two-tier response system with escalation path | Complex systems |
There is no perfect recipe for an on-call rotation. The key is finding the right balance for your team, so talk with them and collect feedback from everyone who'll take part on the rotation before making any definitions. Do take into consideration:
- Business hours vs. off-hours coverage requirements
- Team size and geographical distribution
- Alert volume and complexity
- Work-life balance and local labor laws
Training and skill development
Your incident response team's effectiveness depends on continuous learning and improvement. Start by implementing these training strategies:
Simulation Exercises: Run regular sessions where you deliberately inject failures into your systems (in a controlled environment, of course!). These exercises help your team practice response procedures, build muscle memory for real incidents, and gain confidence in taking part on on-call rotations.
Knowledge Transfer: Create opportunities for experienced team members to mentor newer ones. This might include:
- Shadowing during incident response
- Regular review of past incidents and postmortems
- Technical deep-dives into system architecture
- Communication and leadership skill development
Remember to foster a blameless culture where learning from mistakes is celebrated rather than punished. Your team should feel psychologically safe to experiment, make decisions, and learn from both successes and failures.
To keep your incident response team sharp, maintain a living knowledge base that includes:
- Detailed runbooks for common scenarios
- Documentation of past incidents and resolutions
- Technical system diagrams and dependencies
- Communication templates and escalation procedures
Conducting regular drills and simulations
Practice makes perfect! Regular incident simulations help your team build muscle memory for real emergencies. Start with tabletop exercises and progress to more complex scenarios.
Simulation Types and Benefits:
- Tabletop Exercises: Discussion-based sessions perfect for practicing roles and communication, and a great starting point for new SRE teams.
- One exercised I personally love is the "Wheel of Misfortune", or "Disaster Role Playing". It's a structured training exercise where an engineer, the "Game Master", presents a historical incident scenario, while a participating "Volunteer" engineer works through the problem as if it were happening in real-time. The facilitator acts as all the parts of the system, responding to the participant's actions and queries, allowing them to practice incident response in a controlled, educational environment. You can find a better explanation in Google's SRE Book.
- Purple Team Exercises: Collaborative sessions between defenders and simulated attackers
- Red Team Exercises: Real-world scenario testing without advance warning
Your simulation program should evolve with your team's maturity. Begin with simple scenarios and gradually increase complexity as your team gains confidence. Remember to document learnings from each exercise – they're valuable inputs for improving your incident management process.
4. Tools and Technologies for SRE Incident Management
Let's explore some of the essential technologies that'll transform your SRE practice from reactive to proactive.
Monitoring and observability platforms
Your monitoring strategy needs robust platforms that provide deep insights into system health. Metrics collection and visualization, SLOs tracking, and alerting are all essential tools for diagnosing an incident.
We've already covered the setup of a robust monitoring solution with metrics, SLOs, and alerting with Prometheus and Grafana in a previous post:
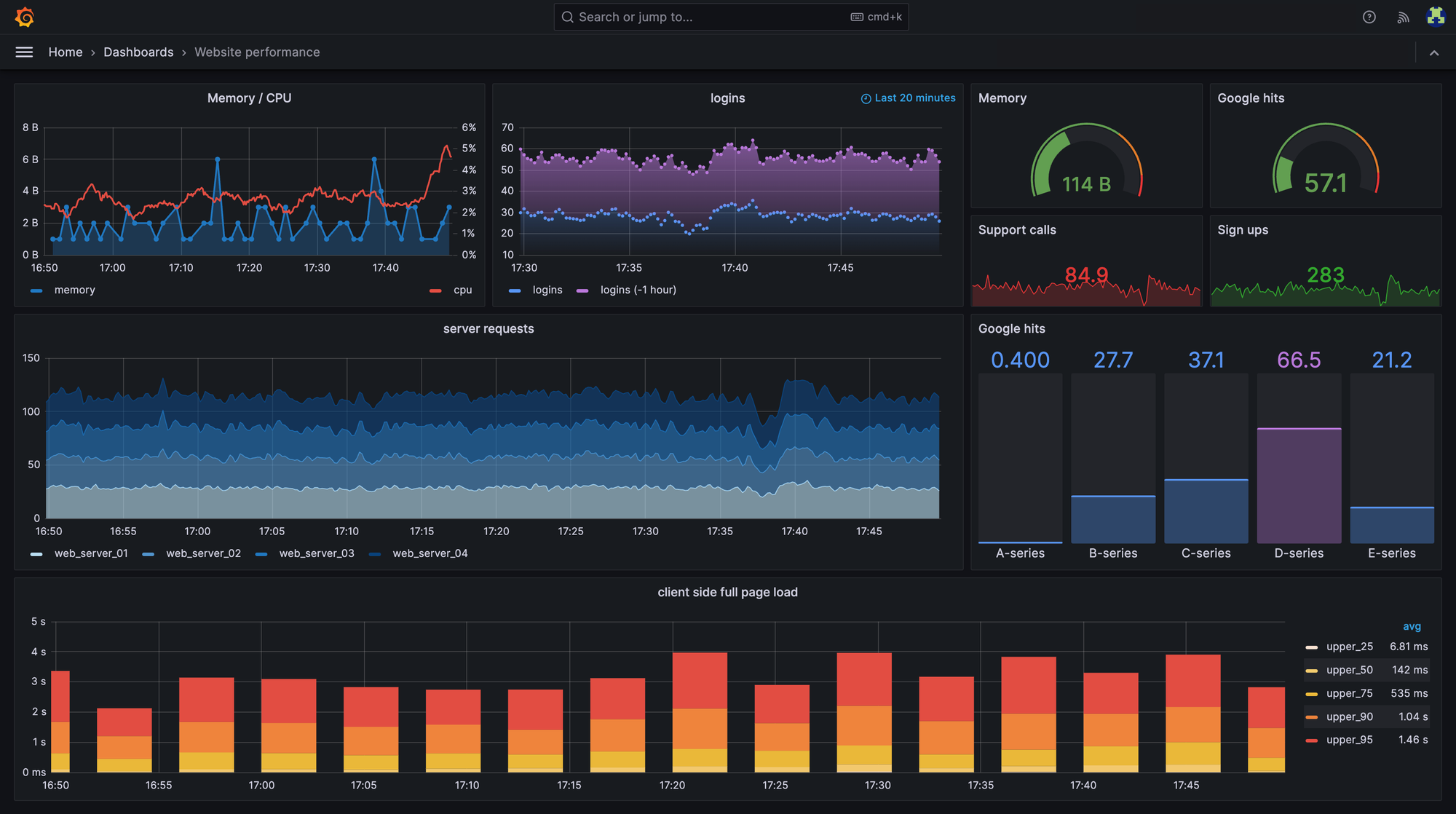
Apart from metrics, you can also level-up your observability stack with structured Logs and Tracing. We'll cover these topics in upcoming posts.
Alerting and notification systems
Your alerting system is the nervous system of your incident management framework. Modern platforms offer sophisticated alerting capabilities that help maintain high signal-to-noise ratios.
Key features to look for in your alerting system:
- Customizable escalation policies
- Multi-channel notifications (mobile notifications, SMS, voice calls, email)
- Alert grouping and noise reduction
- Integration with monitoring platforms
Popular solutions like PagerDuty, and Opsgenie provide these capabilities while offering seamless integration with your existing toolchain.
Collaboration and communication tools
When incidents strike, effective communication is key!
Your collaboration toolkit should facilitate real-time information sharing and team coordination. Modern incident management platforms offer dedicated incident channels, timeline tracking, and updates to stakeholders and customer. PagerDuty, for example, allows for automatically creating Slack channels for each new incident, and serves a Status Page informing your user's of the current status of your systems and communication on ongoing incidents.
Automation and runbooks
Runbooks provides your team with standardized procedures for common scenarios. Modern automation platforms such as Ansible can help you execute these runbooks efficiently, reducing human error and response time. We've covered how to write effective runbooks in our previous post on Monitoring Fundamentals, and we'll be covering automations in upcoming posts.
It's important to note that while runbooks can be an essential tool during an incident, engineers should not solely rely on them. You can't write runbooks for every possible scenario, and your engineering team must be able to effectively troubleshoot new incidents without a step-by-step guide.
5. Best Practices for Minimizing Incident Impact
Implementing Service Level Objectives (SLOs)
Service Level Objectives are your north star for reliability. Your SLOs should reflect what makes your users happy, and can serve as an essential tool to determine the severity level of an issue. With Error Budgets and Burn Rate Alerts you can automate your incident response and make data-driven decisions about the severity level of an incident.
Here's how SLOs benefit your incident management process:
- Incident Priority Assessment: - Compare real-time SLO performance against thresholds - Quickly determine if an issue needs immediate attention - Automatically escalate when error budgets are burning too fast
- Response Time Optimization: - Set clear thresholds for different severity levels - Define automated alerting based on SLO burn rates - Enable teams to focus on truly impactful issues
- Post-Incident Analysis: - Measure the actual impact on user experience - Track error budget consumption during incidents - Identify patterns in SLO violations to prevent future issues
- Proactive Risk Management: - Monitor trending towards SLO boundaries - Implement early warning systems - Balance feature velocity with reliability needs
For example, if your service has a 99.9% availability SLO, you might set up the following incident management triggers:
Critical Incident: Error budget consumption > 2x monthly budget in 1 hour Major Incident: Error budget consumption > monthly budget in 1 day Minor Incident: Error budget consumption > 25% monthly budget in 1 week
Warning: Error budget consumption > 5% monthly budget in 1 weekFor a thorough guide on effectively creating and tracking SLOs, check out our last week's post:
Fostering a blameless culture
Creating psychological safety is crucial for effective incident management. When team members feel safe to report issues early and share their perspectives openly, you'll catch problems before they become major incidents.
Building Blocks of Blameless Culture:
- Focus on systems, not individuals: Look for process improvements rather than human error
- Encourage transparency: Make it safe to admit mistakes and share learnings
- Document everything: Create detailed, objective incident records
- Learn continuously: Use every incident as both a teaching and a learning opportunity
Remember, a blameless culture doesn't mean zero accountability – it means focusing on how to prevent similar incidents in the future rather than pointing fingers. Your postmortems should reflect this by examining circumstances and systems rather than individual actions.
Practical Implementation Tips:
- Start postmortems by explicitly stating the blameless approach
- Use neutral language in incident documentation
- Celebrate learning opportunities
- Share success stories of system improvements
By implementing these best practices, you're not just reducing incident impact – you're building a more resilient organization. Your SLOs provide clear targets, error budgets guide your decision-making, regular drills keep your team sharp, and a blameless culture ensures continuous improvement.
Conclusion
Modern SRE incident management demands a holistic approach where people, processes, and technology work in perfect harmony. Your success relies on building robust response teams with clear roles, implementing comprehensive monitoring systems, and maintaining effective communication channels throughout the incident lifecycle. These elements, combined with automation tools and well-defined runbooks, create a resilient framework that catches issues early and resolves them efficiently.
Organizations that embrace these SRE practices transform their reliability landscape through data-driven decisions and systematic improvements. A strong foundation of service level objectives, error budgets, and regular incident response drills ensures your team stays prepared for any challenge. Most importantly, fostering a blameless culture encourages continuous learning and innovation, making each incident an opportunity to strengthen your systems and processes. Your journey toward operational excellence starts with these proven strategies, building stronger, more reliable systems one incident at a time. 🚀
Subscribe to ensure you don't miss next week's deep dive into Infrastructure as Code! Your journey to mastering SRE continues! 🎯
If you enjoyed the content and would like to support a fellow engineer with some beers, click the button below :)