

Hey there, reliability champions! 👋 This week, giving continuation to our previous post on Monitoring Fundamentals, I'm going to introduce you to one of the most powerful tools in an SRE's belt: Service Level Objectives. If you haven't read last week's post, be sure to check it out here:

Service Level Objectives (SLOs) serve as your organization's compass for measuring and maintaining service reliability. You need clear, actionable SLOs to balance innovation speed with system stability, ensure customer satisfaction, and guide your engineering decisions effectively.
In this comprehensive guide, I hope to help you understand how to define and implement meaningful SLOs that align with your business goals. We'll explore everything from selecting appropriate performance metrics and monitoring strategies to setting realistic targets and establishing effective service level agreements. Whether you're new to SLOs or looking to refine your existing objectives, this guide will help you build a robust reliability framework for your services. 🎯
1. Understanding Service Level Objectives (SLOs)
Let's explore how these powerful tools can transform your reliability engineering practices!
Definition and importance of SLOs
Service Level Objectives (SLOs) are your targeted levels of service reliability, measured over specific time periods. Think of them as your reliability compass, guiding decisions about system performance and user satisfaction. They're rooted in a fundamental principle: service reliability directly correlates with user happiness.
Your SLOs serve multiple crucial purposes:
- Drive positive business outcomes
- Create shared responsibility between development and operations
- Help prioritize engineering work effectively
- Enable data-driven decisions about reliability and innovation
When implemented correctly, SLOs help you achieve reliability and improvements where it matters most - in your users' experience.
Difference between SLOs, SLIs, and SLAs
Let's clarify these three interconnected concepts:
- Service Level Objectives (SLOs):
- These are your specific, measurable targets for service performance. In layman’s terms, service level objectives represent the performance or health of a service.
- These can include business metrics, such as conversion rates, uptime, and availability; service metrics, such as application performance; or technical metrics, such as dependencies to third-party services, underlying CPU, and the cost of running a service.
- For example, a typical SLO might state "99.95% availability on login services", meaning that over a set time frame (e.g 30 days) its expected that the login services should be up for 99.95% of that time.
- Service Level Indicators (SLIs):
- These are the actual metrics you use to measure service performance. They're typically expressed as a ratio of good events to total events, ranging from 0% to 100%.
- Most SLIs are measured in percentages to express the service level delivered. For example, if your SLO is to deliver 99.5% availability, the actual measurement may be 99.8%, which means you’re meeting your agreements and you have happy customers. To gain an understanding of long-term trends, you can visually represent SLIs in a histogram that shows actual performance in the overall context of your SLOs.
- Service Level Agreements (SLAs):
- These are your contractual commitments to customers, often including multiple SLOs, guaranteeing a certain measurable level of a service. When these promises aren't met, there can be financial consequences like service credits or subscription extensions.
What are Error Budgets?
Error budgets are an allowance for a certain amount of failure or technical debt within a service level objective.
For example, if your SLO guarantees 99.5% availability of a website over a month, your error budget is 0.5%. This means that, over the past 30 days you can have around 3.6 hours of disruption.
Error budgets allow development teams to make informed decisions between new development vs operations and polishing existing software. Properly set and defined SLOs should have error budgets that give developers space and confidence to innovate, without negatively impacting operations.
Key components of an effective SLO
To create meaningful SLOs, you need to incorporate these essential elements:
- Measurement Period: Define the time frame over which you'll evaluate performance
- Target Value: Set realistic, achievable goals (industry standard often uses "nines" - like 99.9% or 99.95%).
- 100% is NOT a realistic goal!
- Adding more and more 9s to your reliability target can be quite expensive.
- Measurement Location: Specify where and how metrics are collected
- Expression: Clear language defining what the SLO will measure
Remember, your SLOs should be attainable, measurable, meaningful, and most importantly, aligned with user expectations. When setting targets, resist the temptation to aim for 100% reliability - it's not only unrealistic but often unnecessary for user satisfaction.
2. Identifying Critical User Journeys
Let's explore how to identify the journeys that matter most to your users. Understanding these paths is crucial for setting meaningful service level objectives.
Mapping user interactions with your service
Your users' interactions with your service can span anywhere from a couple to hundreds of touchpoints, depending on the complexity of your product . A Critical User Journey represents a flow through your product that delivers significant business value. Think of it as tracking your users' footsteps through your service landscape.
To map these interactions effectively, consider these key business value categories:
- Financial transactions (like checkout processes)
- Growth opportunities (user registration flows)
- Core service functionalities (search and browse features)
- Visibility actions (social sharing capabilities)
Prioritizing key touchpoints
When prioritizing touchpoints, focus on business impact and user satisfaction. For example, in an e-commerce context, the priority order typically flows as:
- Checkout completion
- Cart management
- Product browsing
Why this order matters: If users can't checkout, you lose revenue and create frustrated customers who've wasted time browsing and selecting items. However, if they can't browse initially, they're more likely to return later without negative sentiment.
Aligning SLOs with user expectations
Your service level objectives must reflect genuine user experiences and expectations. This alignment requires collaboration across multiple stakeholders:
- Product Owners: They anticipate and communicate customer needs
- SRE & Ops Teams: They ensure objectives are realistic and sustainable
- Development Teams: They negotiate reliability vs. velocity tradeoffs
- Customers: They provide direct feedback through various channels
For optimal alignment, consider your users' actual behavior patterns. For instance, if your customer base operates within specific time zones or business hours, your availability requirements could even reflect these patterns. For example, stock markets have different requirements of availability during open or closed markets. Development teams can have a lot more freedom on deploying production changes during closed market hours.
This targeted approach helps you focus resources where they matter most to your users.
3. Selecting Appropriate Service Level Indicators (SLIs)
Let's explore how to choose the right Service Level Indicators (SLIs) that will truly reflect your users' experience.
Types of SLIs for different services
Your service type directly influences which SLIs will be most meaningful. Here's a practical breakdown of essential SLIs based on service categories:
Request-Driven Services
- Availability: Measures the proportion of valid requests served successfully
- Latency: Tracks the percentage of requests served faster than a threshold
- Quality: Monitors service degradation levels
Data Processing Services
- Freshness: Ensures data is updated within acceptable time frames
- Coverage: Tracks successful data processing ratios
- Correctness: Validates output accuracy
- Throughput: Measures processing speed against thresholds
Balancing coverage and complexity
Here's the golden rule: use as few SLIs as possible while accurately representing your service tolerances. Industry best practices suggest maintaining between two to six SLIs. Why this range? Too few indicators might miss crucial signals, while too many can overwhelm your support team with minimal added benefit.
Consider this approach for balanced coverage:
- Focus on user-facing metrics that directly correlate with customer satisfaction
- Prioritize measurements closest to user interaction points
- Combine related metrics when possible to reduce complexity
Best practices for SLI selection
To create effective SLIs, follow these field-tested guidelines:
- Understand Your Users First: Your SLIs should reflect what users actually care about, not just what's easy to measure. For instance, focus on user-observable metrics rather than internal ones like CPU utilization.
- Choose Appropriate Measurement Points: The best place to measure is typically at the front-end load balancing infrastructure – it's usually the closest point to users within your control.
- Keep It Mathematical: When defining SLIs, use clear formulas like:
- Availability = (successful requests / total valid requests) × 100
- Latency = (requests served within threshold / total requests) × 100
- Document and Share: Always maintain clear documentation of your SLIs and share it with your team. This ensures consistency in monitoring and response actions.
- Stay Engaged: Remember that SLIs evolve with your service. Keep iterating and fine-tuning based on user feedback and system performance.
4. Setting Realistic and Meaningful SLO Targets
SLO (Service Level Objective) targets should strike a balance between customer satisfaction and operational feasibility. The key is to set targets based on actual system capabilities and user needs rather than arbitrary "perfection.". Setting realistic and meaningful SLOs is key to guaranteeing SLOs effectively guide your decisions.
Analyzing historical performance data
Your journey to establishing realistic SLOs starts with understanding your service's past performance. Take a quarter or two to gather comprehensive data about your system's behavior. This analysis period helps you:
- Understand planned and unplanned operational impacts
- Map service availability to business indicators
- Identify seasonal variations and patterns
- Establish baseline performance metrics
Remember, your first attempt at setting targets doesn't need to be perfect - the key is getting something measured and establishing a feedback loop for improvement.
Considering business goals and constraints
Setting effective SLOs requires striking a delicate balance between ambition and achievability. Your targets should align with both technical capabilities and business objectives. Here's how to approach this strategically:
- Stakeholder Alignment: Collaborate with product managers, developers, and support teams to ensure complete buy-in. Every link on this chain has to agree and respect the defined SLOs.
- Resource Assessment: Consider your team's current capabilities and constraints
- Customer Expectations: Balance user satisfaction with technical feasibility
- Business Impact: Evaluate how reliability targets affect revenue and growth
5. Continuous Improvement and SLO Refinement
The journey of service level objectives doesn't end with implementation - it's an evergoing process of refinement and evolution.
Regular review and adjustment of SLOs
In the dynamic world of service reliability, your SLOs need regular tune-ups. Running a service with SLOs is an adaptive and iterative process, as significant changes can occur within a 12-month period. New features might emerge, customer expectations could shift, or your company's risk-reward profile might evolve.
Here's your strategic review framework:
- Monthly Health Checks: Quick assessment of current performance
- Quarterly Deep Dives: Comprehensive analysis of trends and patterns
- Semi-Annual Overhauls: Complete review of SLO relevance and targets
- Annual Strategic Planning: Alignment with broader business objectives
When evaluating your SLOs, consider these performance scenarios:
- If you're consistently exceeding your SLO targets, you can:
- Tighten up the SLO to increase service reliability
- Use the unused error budget for product development or experiments
- If you're struggling to meet your SLOs:
- Adjust targets to more manageable levels
- Invest in stabilizing the product before new feature rollouts
Incorporating feedback from stakeholders
Your SLO refinement process should be a collaborative journey. Remember, defining an SLO is a team effort driven by the SRE team but requiring input from multiple stakeholders across your organization.
To maximize stakeholder engagement:
- Schedule weekly stakeholder review sessions
- Limit core project teams to essential members. This ensures an efficient meeting while not being a burden to development teams.
- Create structured processes for feedback collection and analysis
- Ensure regular, focused interactions for beneficial feedback
Evolving SLOs with changing business needs
Your business landscape is constantly shifting, and your SLOs must evolve accordingly. Continuous improvement processes enable organizations to proactively respond to changes in the marketplace, customer demands, and industry trends.
To maintain effective evolution:
- Monitor and Evaluate: Track key metrics and compare performance before and after improvements. This data-driven approach ensures your SLO adjustments are based on concrete evidence rather than assumptions.
- Build a Culture of Innovation: Foster an environment that:
- Encourages experimentation and adaptation
- Promotes continuous learning
- Supports ongoing improvement efforts
- Enables evolution as organizational needs change
- Overcome Resistance to Change: Clear communication is crucial when implementing new improvement initiatives. Leaders should:
- Communicate reasons for change and benefits
- Seek input from key stakeholders
- Foster a supportive environment
- Recognize and reward contributions
Remember, continuous improvement is a never-ending cycle. Your SLOs should reflect real-time data utilization and employ monitoring tools to track performance. When user latency begins to creep up, it might be time to reevaluate and tighten your SLO.
By maintaining this cycle of continuous improvement, you'll ensure your SLOs remain meaningful, actionable, and aligned with both user expectations and business objectives. Remember to celebrate milestones along the way - each refinement brings you closer to optimal service reliability!
6. Implementing SLO Monitoring and Reporting
Let's explore how to implement effective monitoring and reporting systems that keep your reliability goals on track!
Tools and techniques for SLO tracking
Your monitoring journey begins with selecting the right tools. Cloud Monitoring collects metrics that measure service infrastructure performance, while providing flexibility to define custom service types and select specific performance metrics for tracking.
For effective SLO tracking, you must implement these key components:
- Data Collection Systems: Set up monitoring at your front-end load balancing infrastructure for accurate user experience metrics, such as Grafana or DataDog
- Time Tracking Mechanisms: Implement specific time frames for SLA monitoring
- Automated Notifications: Configure instant alerts for SLO breaches
- Historical Data Analysis: Maintain records for trend analysis and reporting
The Burn Rate Metric
Burn Rate is a metric that shows how quickly you're consuming your error budget relative to your Service Level Objective (SLO) threshold. It's calculated as the rate of errors during a recent time window divided by the rate of errors you've budgeted for. For example, if your SLO allows for 0.1% errors over a month but you're experiencing 0.2% errors in the last hour, your burn rate would be 2x – meaning you're consuming your error budget twice as fast as sustainable.
A high burn rate serves as an early warning system, alerting teams that they're depleting their error budget faster than planned and allowed for. Instead of waiting until the end of the SLO period to discover you've exceeded your error budget, burn rate helps teams identify and respond to issues before they become critical. For instance, a burn rate of 10x might trigger immediate incident response, while a burn rate of 1.5x might just warrant increased monitoring.
Creating effective dashboards
Your SLO dashboard serves as a visual command center for service reliability. When designing dashboards, focus on these essential elements:
- Real-Time Updates: Ensure your dashboard displays current data for immediate action
- Historical Context: Include trend analysis to understand patterns
- Interactive Elements: Enable drill-down capabilities for detailed analysis
- Role-Based Views: Customize displays based on user needs and responsibilities
Remember to maintain consistency in your dashboard design - use the same formats, colors, and terminology throughout to avoid confusion. Your dashboard should provide different levels of granularity depending on the audience, from high-level service health to detailed performance breakdowns.
Establishing alert thresholds
Alert configuration requires careful consideration of your error budget and burn rates. The burn rate indicates how quickly you're consuming your error budget relative to your SLO.
For optimal alerting, consider this multi-window approach:
- Short-term alerts: Configure notifications for rapid error budget consumption that could lead to immediate issues.
- Long-term monitoring: Set up alerts for slower degradation patterns that might affect your compliance period.
Your alerting configuration should include:
- Precision metrics to reduce false positives
- Detection time optimization for quick response
- Reset time parameters for alert resolution
For maximum effectiveness, implement a tiered alerting approach based on error budget consumption. For instance, you might want to receive a warning when you've spent 5% of your error budget, and a critical alert at 10% consumption.
7. Hands-On: Implementing and Visualizing SLOs in Grafana
Now that we have covered all fundamentals of Service Level Objectives, let's get our hands dirty by creating our first SLO and visualizing it, along with its error budget and burn rate metrics, all on a beautiful Grafana dashboard!
To help us create the SLO metrics, alerts, and dashboards we are going to use the awesome open-source project Sloth. With Sloth, we can define our SLO in a nice .yaml file, and it takes care of all the rest for you – automatic SLI rules, pre-defined dashboards, ...
To get started, first Install Sloth by following their official documentation. There are various options for running, or locally building, this tool.
As of November 13, 2024, I am rewriting this section using Pyrra instead, which serves a similar purpose but is being actively maintained and updated. I expect to have it ready this week.
Defining our SLO
Now that you have installed Sloth, we can get ready defining our SLO specification. Sloth expects a YAML file to describe the Service Level Objective you want to create.
Let's create an example SLO for our Golang service, which tracks error rates on logins. To start, create a new file under slos/login_errors.yaml and let's configure it with the following content:
version: "prometheus/v1"
service: "go-service"
labels:
owner: "my_team"
repo: "jpereiramp/52-weeks-of-sre-backend"
tier: "1" # Defines the priority (a lower value means a higher priority)
slos:
# We allow failing (5xx and 429) 1 request every 1000 requests (99.9%).
- name: "requests-availability"
objective: 99.9
description: "Common SLO based on availability for HTTP request responses."
sli:
events:
error_query: sum(rate(http_requests_total{handler="/auth/login"}[5m]))
total_query: sum(rate(http_errors_total{handler="/auth/login", status=~"5.*"}[{{.window}}]))
alerting:
name: LoginsHighErrorRate
labels:
category: "availability"
annotations:
# Overwrite default Sloth SLO alert summmary on ticket and page alerts.
summary: "High error rate at 'go-service' login requests"
page_alert:
labels:
severity: page_team
routing_key: my_team
ticket_alert:
labels:
severity: "discord"
slack_channel: "#alerts-my-team"
Now we'll use Sloth to generate all alert rules required for keeping track of our Logins SLO! Simply run the following command, which will read the slos/login_errors.yaml specification file and output a login_slo_rules.yaml file containing all alert rules we need for the SLO:
$ ./sloth generate --input=./52-weeks-of-sre-backend/slos/login_errors.yaml -o login_slo_rules.yamlConfiguring Alerts in Prometheus
Now that we have our Alert Rules we must update our Prometheus deployment so that it sees this new login_slo_rules.yaml configuration file. First, move this file to the existing config/prometheus directory, and then edit the config/prometheus/prometheus.yml file by adding the following content:
global:
scrape_interval: 15s
rule_files:
- "login_slo_rules.yaml" # Add our Login SLO rules file
scrape_configs:
// Code remains the same...
We must also update our docker-compose.yml file in order in order to map the login_slo_rules.yaml file to the Prometheus container:
prometheus:
// Initial code stays the same ...
volumes:
- ./config/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- ./config/prometheus/login_slo_rules.yaml:/etc/prometheus/login_slo_rules.yaml
// Remaining code stays the same ...Finally, run a docker-compose up -d command to update your Prometheus container, and access http://localhost:9090 , under "Alerts", and verify that your newly created SLO Alert Rules are there!
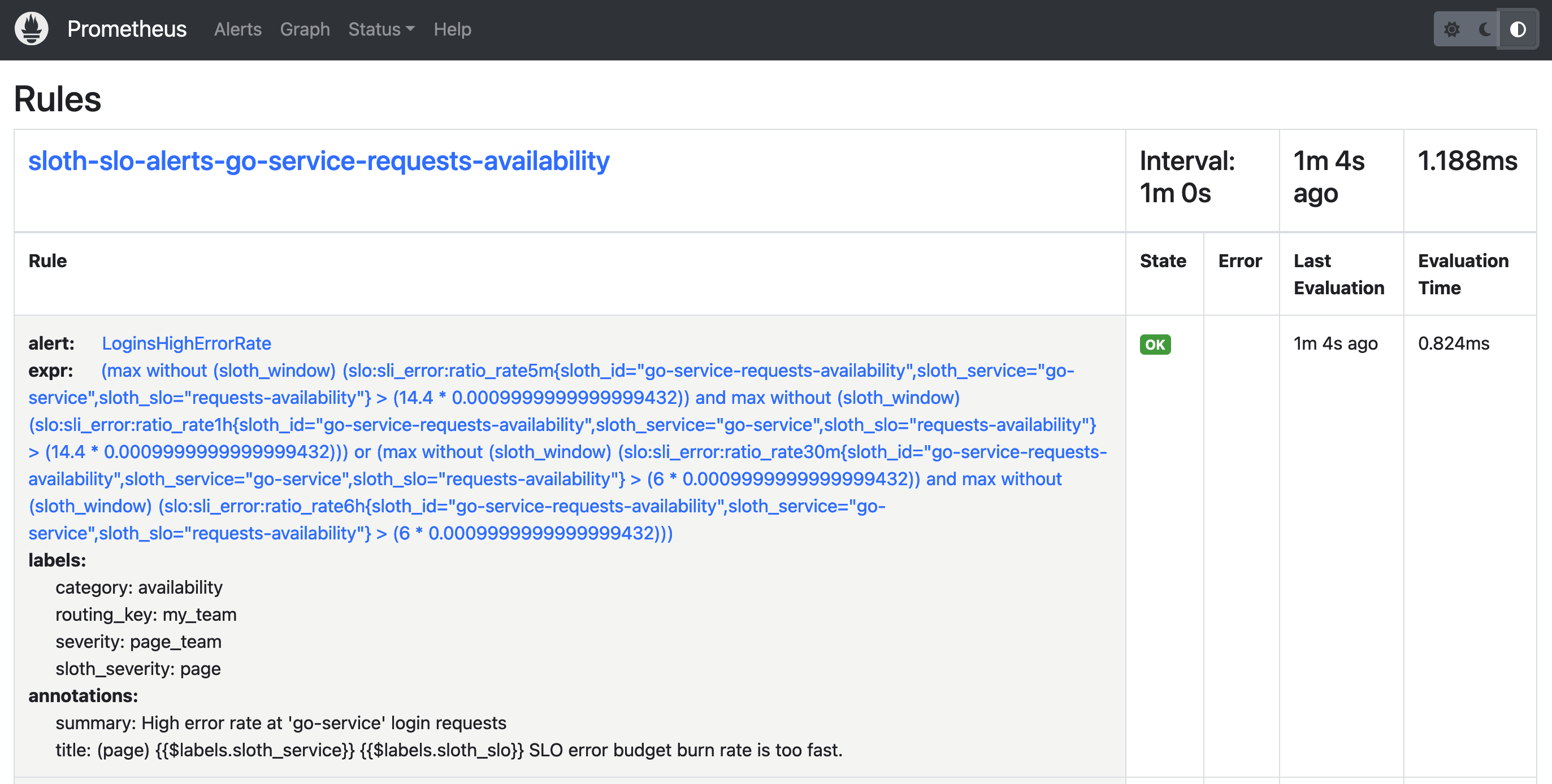
Awesome! Now Prometheus is keeping track of our Logins Availability SLO, but we need a better way to visualize this data!
Creating SLO Visualizations in Grafana
Sloth also provides you with a couple of pre-defined dashboards that beautifully render your SLOs automatically! They're also a great starting point if you want to build your own custom SLO dashboard – just copy the pre-made visualizations over to your dashboard.
There are two Dashboard options available, each serving their own important purpose: SLO Details and SLOs Overview. The first is great for getting in-depth data about a specific SLO, while the latter is perfect for getting a general idea on your entire platform's health, and a great dashboard for stakeholders!
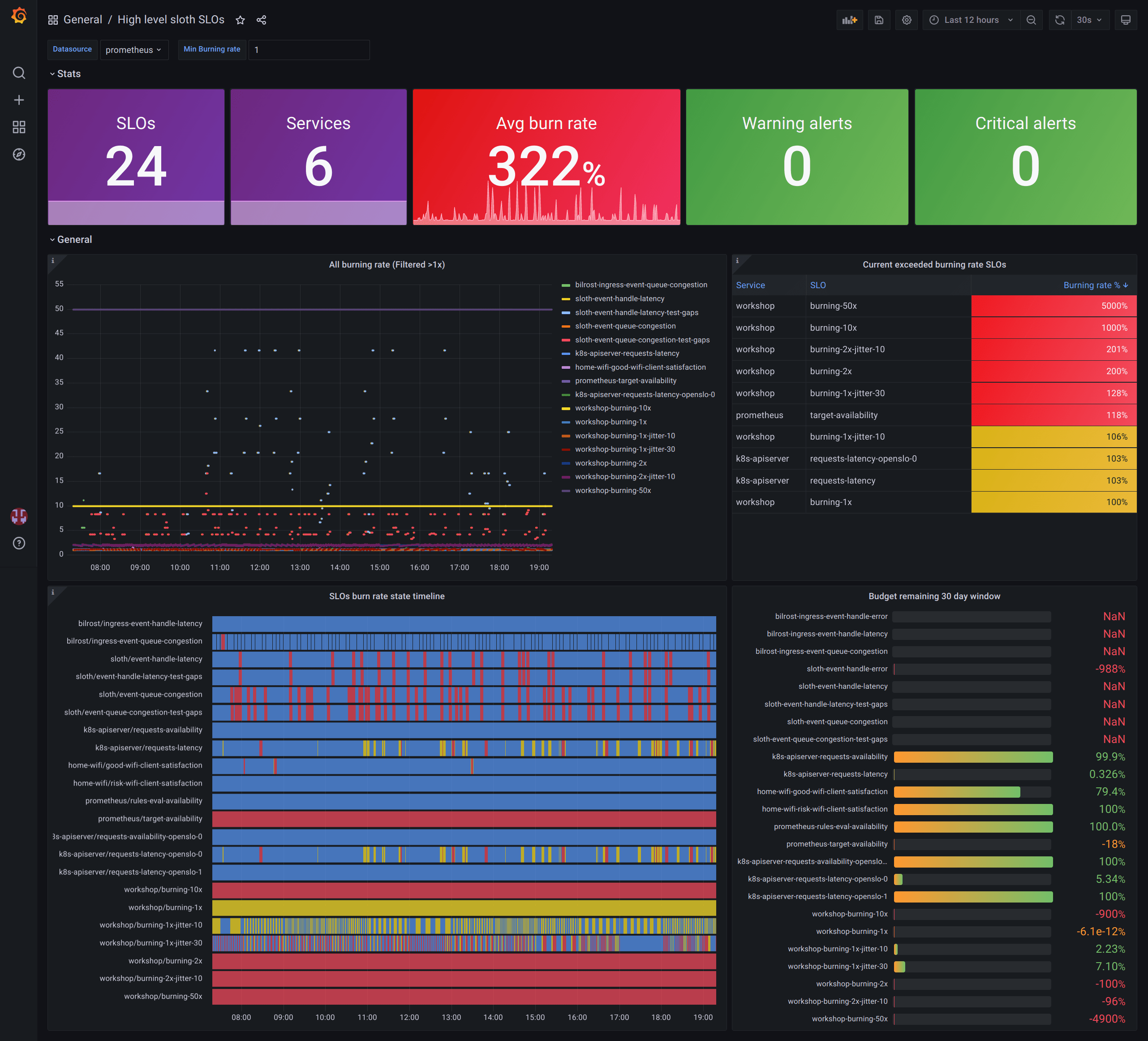
In order to import these dashboards over to your Grafana instance, you can head over to their pages in Grafana and either download their JSON files, or copy their "Dashboard ID".
With the Dashboard's JSON or ID in hands, go to "Dashboards" under your Grafana instance, and go to New -> Import. Now simply attach the JSON or set the Dashboard ID, then select your Prometheus Data Source, and you're done! 🎯
As always, our "52 Weeks of SRE" GitHub Repository is kept up-to-date, and I've included all relevant files, including proposed exercises, that we worked on throughout this article.
 jpereiramp
jpereirampConclusion
Service Level Objectives stand as essential guides for modern organizations, enlightening the path toward reliable service delivery and customer satisfaction. Your SLO journey demands careful consideration of user expectations, precise metric selection, and realistic target setting. These elements, combined with robust monitoring systems and stakeholder collaboration, create a solid foundation for service reliability management that drives business success.
Data-driven refinement and continuous improvement shape the evolution of your SLO framework, ensuring its relevance amid changing business needs. Regular reviews, stakeholder feedback, and performance analysis help maintain effective service levels while supporting innovation. Your commitment to measuring what matters most - the user experience - transforms abstract reliability goals into concrete, achievable targets that benefit both your organization and its customers.
Continue your learning
If you want to read more on SLOs and deepen your knowledge on this key SRE concept, I highly suggest the Implementing Service Level Objectives: A Practical Guide to SLIs, SLOs, and Error Budgets book by Alex Hidalgo.
Subscribe to ensure you don't miss next week's deep dive into Incident Management! Your journey to mastering SRE continues! 🎯
If you enjoyed the content and would like to support a fellow engineer with some beers, click the button below :)