

Howdy, SRE enthusiasts! 👋
Monitoring is a fundamental aspect of Site Reliability Engineering that involves collecting, processing, aggregating, and displaying real-time data from one or more systems. It's this data that helps engineers understand their system's behavior, health, and performance. In modern distributed systems, effective monitoring is not just beneficial—it's essential for maintaining reliable services.
If you didn't see last week's post on SRE Fundamentals, make sure to start your journey there!

In this introductory post to Monitoring, I'll focus on one strategy that we can use for monitoring: metrics, however many of the concepts exposed here can be applied to all strategies. Throughout the "52 Weeks of SRE" series we'll look into other monitoring solutions such as Logs, and Distributed Tracing.
Introduction
What is Monitoring in SRE?
Monitoring in the SRE context goes beyond simply watching metrics. It's a comprehensive approach to systems observability that involves:
- Collecting metrics about your applications and the infrastructure powering them
- Processing and analyzing these metrics in real-time
- Generating alerts when systems behave abnormally
- Visualizing data to make informed decisions
- Tracking system changes and their impacts
For example, if you're running an e-commerce web application, monitoring might track metrics like response times, error rates, database connection pool status, and CPU utilization across your entire infrastructure. You may also track other application-specific metrics, such total sign-ups, and number of items added to cart.
Let's talk more about both of these kinds of metrics.
Black-box vs. White-box Monitoring
Monitoring strategies typically fall into two categories: black-box and white-box monitoring. Both are crucial for a complete monitoring solution.
Black-box Monitoring
- Tests system behavior from the outside, like an end user would experience it
- Focuses on system outputs and external behaviors
- Examples:
- HTTP endpoint availability checks (can I reach this endpoint?)
- API response time measurements (is this request taking too long?)
- End-to-end transaction tests (did this operation fulfill all of its requirements?)
White-box Monitoring
- Examines system internals and detailed metrics
- Provides insights into system behavior and performance
- Examples:
- Memory usage and garbage collection metrics
- Database query performance
- Internal queue lengths (e.g. monitoring a Kafka consumer's offset lag)
- Cache hit rates
- Application-specific metrics (e.g., active checkout sessions, total orders processed, ...)
Alerts and Dashboards
Monitoring data needs to be presented in ways that help engineers make decisions and take actions. With metrics, this is primarily done through two mechanisms: alerts and dashboards.
Alerts
Alerts are automated notifications, sent to specific channels, that are triggered when specific conditions are met in your system. They serve as a proactive mechanism to notify engineers about potential issues, so they can act before that issue impact more users.
Key Components of an Alert
Alert Rule
An alert's rule defines the conditions that triggers the alert. It's expected that these rules will be constantly reviewed: if a system fails but an existing alert was not triggered, then that rule might be too permissive. On the other hand, if an alert is triggered but there is no real issue, or it has been automatically resolved, then that rule might be too aggressive. The latter is often a cause of Alarm Fatigue.
alert: High Error Rate
expresssion: (sum of failing requests) / (sum of total requests) > 5%
for: 5m
labels:
severity: critical
annotations:
summary: High Error Rate for Requests
description: Requests error rate is over 5% for the last 5 minutes
Example Alert Rule
Alert Context
An alert's context provides information that helps to diagnose and fix the underlying issue. This should be easily accessible by the engineer handling the alert, and is what should be sent to the desired notification channel (e.g Slack, Discord, ...)
Alert Title: High Error Rate for Requests
Service: user-service
Severity: Critical
Error Rate: 15% (30/50 requests failed)
Duration: 5 minutes
Affected Endpoints: GET /users, POST /subscribe
Dashboard: https://grafana/d/your-dashboard-id
Runbook: https://runbook/http-errors
Example Alert Context
Severity Levels
Alerts should have different levels of urgency, related to the impact that it represents. This is important so that engineers can properly handle each incoming alert at their required priority, and crucial if you have on-call rotations in order to avoid unnecessary burnouts.
You should aim to have at least the following levels:
- Critical: Immediate action required (e.g. error rate on payments service is at 80%). For systems requiring on-call rotations, these alerts should page the on-call engineer.
- Warning Issue needs attention, but no immediate action required (e.g. 1% of requests to login failed in the past 5 minutes).
Best Practices for Alerts
1. Alert on Symptoms, Not Causes
Prioritize alerting on what the users experience, rather than on internal system metrics.
- ✅ Recommended:
- "API success rate below 99.9%"
- "Payment processing latency > 10s"
- "Error rate exceeded 5% in the last 5 minutes"
- ❌ Avoid:
- "High CPU usage on API server"
- "Network packets received increased"
- "Low disk space on server"
2. Alerts must be Actionable
Every alert should require human intervention and have a clear resolution path. If an alert is triggered but there's nothing an engineer can do to resolve it, then it shouldn't be an alert.
Let's take for example a common operation on database systems: failover. Say one instance of your database crashes, and an automatic failover procedure is started in order to move requests to the other healthy instance. Instead of adding automated alerts for every failover operation that happens in your system, which are not actionable (the operation was automatically triggered and is remediating a real issue), you should focus on creating meaningful alerts on the database and its dependent systems.
For example, a more appropriate alert rule would trigger instead on "Connections to Database dropped to zero", or ">10% of requests to persist data are failing over the last 5 minutes".
3. Metric Types
For each metric that you'll be monitoring, you should choose an appropriate metric type for it. Following are the most common types of metrics and their purposes.
- Counter:
- Used for values that only increase
- e.g. Total number of requests, Total errors, Bytes sent/received
- Gauge:
- Used to track values that can go up and down
- e.g. Memory usage, Active connections, Queue size
- Timer/Histogram:
- Used for measuring duration and their distributions amongst different percentiles, which represent the distribution of values in a dataset.
- Commonly used percentiles are 50th (median), 95th, and 99th. This can give you valuable insight into the experience of most users, for example when looking at the 99th percentile which would indicate the experience of 99% of your users. They're also commonly described as p50, p95, and p99.
- Percentiles are also a great way of dealing with outliers, and can provide a more accurate representation of the majority.
- e.g. Request Latency, Transaction Duration
4. Be mindful of your Alert Thresholds
- Use historical data to periodically review and set new baselines
- Implement multiple severity levels
- Allow for brief spikes with time windows (e.g. evaluate the average over last 5 minutes to better deal with outliers)
5. Have a Clear Runbook
Every alert should be actionable, and the actions to investigate, remediate, and communicate on an alert should be documented in a runbook. Your alerts should include, within their context, a link to this runbook.
Here is a quick draft of an example Runbook for dealing with an alert describing a High API Latency issue on login requests:
# Alert: High API Latency on Login
## Description
API response time exceeded threshold of 10s on login requests
## Impact
- User fails to login
- Violation of SLA
- New users can still use the app
## Investigation Steps
1. Check for recent changes to the login service
2. Verify database performance metrics
3. Review database and login service error logs
## Resolution Steps
1. [Immediate Action] Scale up API servers if needed
2. [Investigation] Review slow query logs
3. [Mitigation] Enable cache if applicable
## Escalation Path
1. On-call SRE
2. Database team (if DB-related)
3. Senior SRE lead
## Related Dashboards
- API Performance Dashboard: [link]
- Database Metrics: [link]
Example Alert Runbook
6. Regularly Review your Alerts
- Review alert frequency and effectiveness monthly
- Track alert response times and false positives
- Update thresholds based on system changes
- Archive or modify alerts that are no longer relevant
7. Be mindful of metric labels
- Metrics are usually accompanied by a set of labels, which are key-value pairs providing extra information about an individual data point. For example, for a metric that tracks API Errors, common labels could be
HTTP StatusandAPI Endpoint. Labels are really useful for getting more information about a data point, but we need to be careful with them! - By "cardinality" we refer to the number of distinct values a label can take on. So a high-cardinality metric means that one or more of its labels contains a large number of unique values, which can result in performance and cost implications to your monitoring stack.
- A low-cardinality metric would be something like
HTTP Method, which we know to be a limited set of <10 options (i.e. GET, POST, PUT, OPTIONS, PATCH, DELETE ....). - A high-cardinality metric would be something like
Timestamp,User ID(in a large dataset),IP Address. Basically, data that have a non-finite, or very large set of possible values.
Dashboards
Dashboards are essential tools for Site Reliability Engineers, providing visual representations of system metrics over time. They enable engineers and stakeholders to understand trends, investigate issues, and make informed decisions. Let's explore some best practices on creating and maintain effective dashboards.
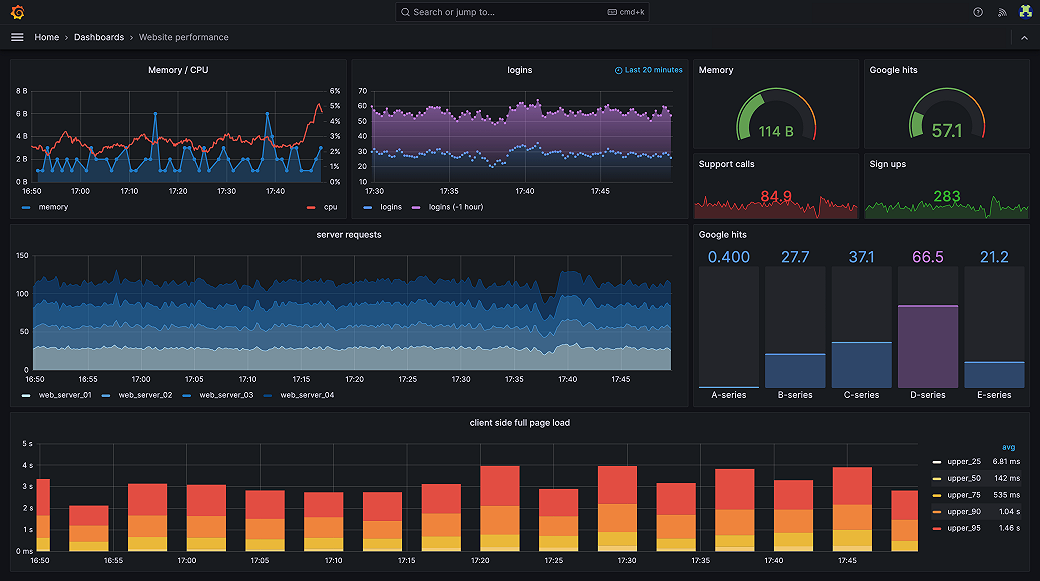
First, let me introduce some of the most common observability strategies that we see for building dashboards:
1. Monitoring Infrastructure: The USE Method
The USE method is best for building dashboards that tracks hardware resources in infrastructure, such as CPU, memory, and network devices. It tells you how happy your machines are.
- Utilization: Percent time the resource is busy (e.g., CPU usage)
- Saturation: Amount of work a resource has to do (e.g., queue length)
- Errors: Count of error events
2. Monitoring User Experience: The RED Method
The RED method is most applicable to building dashboards for services, especially a microservices environment. Each of your services should measure the following metrics for each of their operations.
A well-designed RED dashboard is a proxy for user experience, telling you how happy your customers are.
- Rate: Requests per second
- Errors: Number of failing requests
- Duration: Request latency distribution
3. Industry-standard: The Four Golden Signals
According to the Google SRE handbook, if you can only measure four metrics of your user-facing system, focus on these four.
This method is similar to the RED method, but it includes saturation.
- Latency: Time to serve requests
- Traffic: System demand
- Errors: Failed request rate
- Saturation: System fullness
We'll dedicate more time to talk about the Four Golden Signals in the coming sections of this post.
The best practice for alerting is to alert on symptoms rather than causes, so focus on alerting on RED/Four Golden Signals dashboards.
Types of Dashboards
When building your dashboard, think: "What story am I trying to tell through this dashboard?", and "Who will be its primary users?". These questions should guide you in what type of dashboard you should build.
Let's explore some of the most common types of dashboard:
1. Overview Dashboards
- Provides a quick visualization for understanding the overall health of a system
- Should enable rapid acknowledgement of anomalies
- Include key metrics like p95 latency, total errors, and total hits which gives a general overview of how users are experiencing the system.
2. Service-Specific Dashboards
- Offers detailed data about individual services and their internals
- Helps to isolate, identify, and diagnose specific system issues
- Include internal metrics like CPU Usage, Queue sizes Cron job statuses, ...
3. Business Metric Dashboards
- Focus on business-oriented metrics
- Designed for non-technical stakeholders
- Track business relevant metrics such as New Sign-ups, Total Revenue, Conversion Rates...
Best Practices for Dashboard Creation
1. Visualization Selection
There are a variety of different visualizations supported by most modern monitoring systems. I'll highlight some of the most common ones, but you can read more about the available options here.
- Line Graphs (Time-Series Data)
- Best for: Latency, request volumes, error rates
- Shows variations over time
- Useful for trend analysis (e.g. how are users engaging with this new feature over the past 3 months?)
- Gauges (Utilization Metrics)
- Best for: CPU, Memory, SLOs ...
- Shows current values within defined ranges
- Quick visual reference for resource usage and limits.
- Tables (Detailed Breakdowns)
- Best for: Complex reports, database queries
- Multiple dataset visualization
- Detailed analytical views
- Heat-maps (Distribution)
- Best for: Pattern identification over time
- Value distribution visualization
- Temporal pattern analysis
2. Dashboard Management
- Design Principles
- Tell a clear story or answer specific questions
- Reduce cognitive load, avoid having a "everything dashboard"
- Use consistent naming conventions (e.g. for panels, dashboards, and alerts)
- Include documentation through runbooks and dashboard and alert descriptions
- Maintenance
- Regular review and cleanup of dashboards
- Version control for dashboard configurations
- Proper tagging and organization of monitoring resources
- Avoid dashboard sprawl. Here's a great article on dealing with that.
- Technical Considerations
- Set appropriate refresh rates
- Use template variables for reusability
- Ensure efficient queries
- Monitor impacts to your backend systems – be mindful of your
/metricsendpoint overall size
The Importance of Monitoring
Understanding why we monitor systems is crucial for implementing effective monitoring strategies. Modern systems are complex, and without proper monitoring, we're essentially running blind. Let's explore the key reasons why monitoring is essential.
Proactive Problem Detection
The ability to be alerted on and detect issues before they impact a majority of users is perhaps the most crucial aspect of monitoring. This "early warning system" empowers us to:
- Detect anomalies before they become failures
- Identify performance degradation trends
- Spot resource constraints before they're critical
Performance Optimization
Monitoring data is crucial to optimize system performance and resource utilization.
- Application Performance
- Identify slow database queries
- Track cache hit rates
- Monitor API endpoint latency
- Resource Efficiency
- Analyze CPU and memory usage patterns
- Track storage usage trends
- Monitor network bandwidth utilization
Capacity Planning
Effective monitoring enables data-driven capacity planning decisions.
- Peak Usage Patterns
- Daily peaks during business hours
- Weekly peaks on Mondays
- Seasonal peaks during holidays
- Growth Indicators
- User registration rate
- Data storage consumption
This is crucial information to engineers and stakeholders. Not only it can help you better understand the usage patterns of your users across time, which can be a valuable business insight, it can also inform engineers on how to better prepare for expected changes in demand.
Business Insights
Monitoring isn't just for technical metrics—it can provide valuable business insights as well! Let's take a look at the following examples:
- User Engagement
- Active users per hour/day/month
- Session duration
- Feature usage statistics
- Revenue Impact
- Transaction success rate
- Payment processing times
- Shopping cart abandonment rate
- Customer Experience
- Page load times
- Error rates by user segment
- API availability by region
Cost Optimization
Monitoring can also help to identify opportunities for cost reduction and optimization. From an infrastructure perspective, teams can use monitoring to identify underutilized resources that could be scaled down, track detailed cloud service usage patterns to optimize spend, and ensure auto-scaling mechanisms are operating efficiently. When it comes to performance costs, monitoring enables teams to pinpoint expensive database queries that need optimization, understand how effectively caching mechanisms are being utilized, and identify opportunities to optimize network traffic patterns and reduce associated costs.
System Understanding
Comprehensive monitoring will also help engineering teams to better understand their systems. By analyzing system behavior, teams can establish baselines for normal operating patterns, characterize peak usage scenarios, and map out complex dependencies and interactions between system components. When it comes to understanding change impact, monitoring provides crucial insights into how deployments affect system performance, how configuration changes ripple through the environment, and how infrastructure updates influence overall system stability.
The Four Golden Signals
The Four Golden Signals, popularized by Google's Site Reliability Engineering book, are key metrics that indicate the health and performance of user-facing systems. These signals provide a balanced and comprehensive view of your service's health, while also serving as a proxy to your customers' experience.
Latency
Latency tells the story of your users' experience by measuring how long operations take. Consider an e-commerce platform: while the homepage might load in 200ms for most users (p50), some users during peak shopping periods might experience loading times of 800ms (p90) or even 2 seconds (p99). These percentile measurements paint a more accurate picture than averages alone.
A crucial distinction in latency monitoring is separating successful and failed requests. For instance, when a payment gateway timeout occurs, a failed payment request might take 30 seconds to return an error, while successful payments typically complete in under 500ms. Mixing these measurements would skew your understanding of actual service performance.
Real-world example: Netflix monitors video streaming latency across different stages:
- Initial buffer time: How long before playback starts
- Re-buffer ratio: Time spent buffering vs. playing
- Time to first frame: Speed of video startup
Traffic
Traffic measurements reveal how your system is being used. Rather than just counting requests, think about traffic in terms of user behavior and business impact. For a social media platform, meaningful traffic metrics might include:
- Content creation actions (posts, comments, likes)
- Content consumption patterns (feed refreshes, profile views)
- Peak usage periods across different time zones
The key is measuring traffic in ways that directly relate to your service's purpose. For instance, an online learning platform might care more about "minutes of video watched" or "assignments submitted" than raw request counts. That's not to say that raw request metrics are bad – they're a great starting point!
Errors
Error monitoring goes beyond counting HTTP 500s. Consider a video streaming service: a successful HTTP response that delivers unwatchable, low-quality video is still a failure from the user's perspective.
Common error patterns to watch for:
- Authentication failures that might indicate security issues
- Payment declines that impact business revenue
- Data validation errors that suggest UI or API contract problems
Modern error monitoring requires understanding context. For instance, a spike in checkout errors during a flash sale needs different urgency than the same number of errors during normal operation.
Be specially careful with how your services throw different errors. Client errors, such as a malformed or invalid request body (e.g. a malformed JSON, or invalid email address) are Client Errors and should be treated as such. Client errors usually live within HTTP's 4xx status codes family. Server errors on the other hand are usually thrown as HTTP's 5xx. Your monitoring system should treat these differently: you don't want to wake up an on-call engineer because some user is mistyping their e-mail!
Saturation
Saturation warns you before resources run out. Think of it like a car's fuel gauge – you want to know when to refuel before you're running on empty. Different services have different saturation indicators:
- For databases:
- Connection pool utilization might indicate incoming request pressure
- Storage capacity trends show when to provision more space
- Query execution times may reveal index efficiency issues
- For a message processing system:
- Queue depth indicates processing backlog
- Consumer lag shows how far behind real-time you are
- Processing rate versus incoming message rate reveals system health
- For API services:
- Thread Pool utilization might indicate few threads available to process incoming requests
- Total Active Requests might indicate fewer capacity for handling new requests
Bringing It All Together
These signals work best when viewed holistically. For instance, during a flash sale by a fictional e-commerce platform:
- Traffic spikes show increased demand
- Latency might rise as systems scale
- Error rates could increase if capacity is insufficient
- Saturation metrics reveal which resources need attention
The art lies in setting appropriate thresholds and understanding the relationships between these signals. A latency increase might be acceptable during traffic spikes if error rates and saturation remain within bounds.
Building Effective Monitoring Systems
Every effective monitoring system must answer two crucial questions: "What's broken?" and "Why is it broken?".
Let's explore how to build a system that answers these questions efficiently.
What's Broken?
Service Health
Modern applications require monitoring across multiple dimensions of health. For instance, an e-commerce platform needs to track not just if the checkout service is running, but how well it's performing. This includes monitoring successful vs. failed transactions, response times across different geographic regions, and specific error patterns that might indicate deeper issues.
Resource Status
Rather than tracking every possible metric, focus on resources that directly impact your service quality:
- CPU and Memory: Track patterns that affect user experience, such as garbage collection pauses in a Java application that could cause request latency spikes. For example, a batch processing system might monitor CPU patterns during peak processing hours to automatically scale resources.
- Storage and Network: Monitor metrics that impact your specific use case. A video streaming service cares more about network throughput and buffering times, while a database service prioritizes disk I/O and storage latency.
Business Impact
Connect technical metrics to business outcomes. A hotel booking system should monitor not just server health, but completed bookings, failed payment attempts, and booking abandonment rates during the payment process. This helps to prioritize technical issues and improvements based on their actual impact on the business.
Why Is It Broken?
System Metrics
Instead of collecting every available metric, focus on telling a story with your data. For instance, if your payment processing service is experiencing delays, you'd want to see:
- API gateway latency trends
- Database connection pool status
- Payment processor response times
- Queue depths for asynchronous processes
This combination of metrics helps to isolate and pinpoint whether the issue is internal or with an external dependency, and on which component it might be.
Application Logs
Structure your logging to answer specific questions. When debugging a failed payment, your logs should tell a clear story.
[2024-10-30 14:23:15] Payment attempted for order #12345
[2024-10-30 14:23:15] Validating payment details...
[2024-10-30 14:23:16] External payment gateway timeout after 30s
[2024-10-30 14:23:16] Retry #1 initiated
[2024-10-30 14:23:46] External payment gateway timeout after 30s
[2024-10-30 14:23:50] Retry #2 initiated
[2024-10-30 14:24:20] External payment gateway timeout after 30s
[2024-10-30 14:24:20] Retries exhausted. Sending payment attempt to dead letter queue.
[2024-10-30 14:24:21] Payment attempt for order #12345 sent to DLQ.
Note that we'll add log capabilities to Grafana in upcoming posts. Stay tuned for that!
Dependencies
Modern applications often fail due to external dependencies. A microservices architecture should maintain a dependency map showing the health and performance of service-to-service communications. For example, if your product catalog service becomes slow, you can quickly see if it's due to a degraded database connection, cache unavailability, or an overwhelmed product image service.
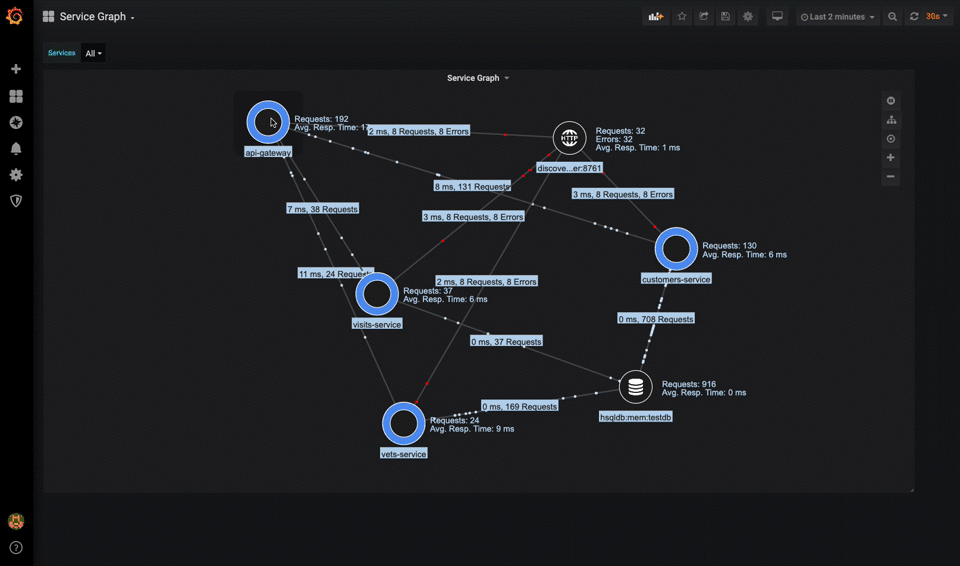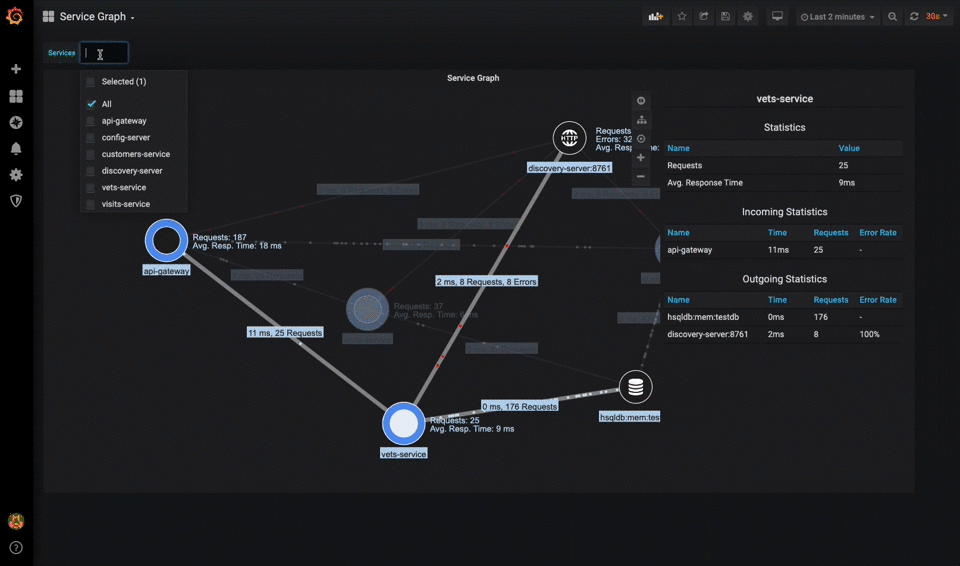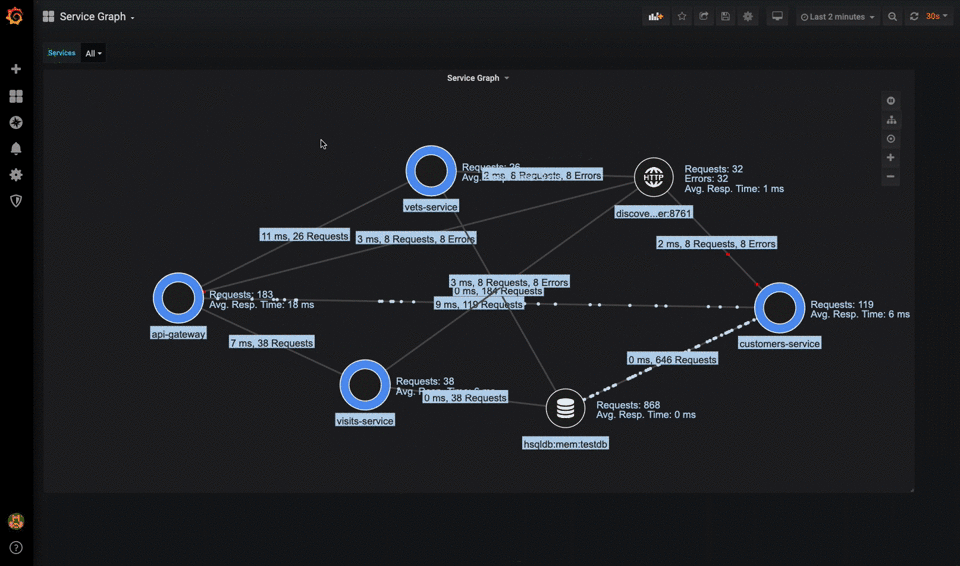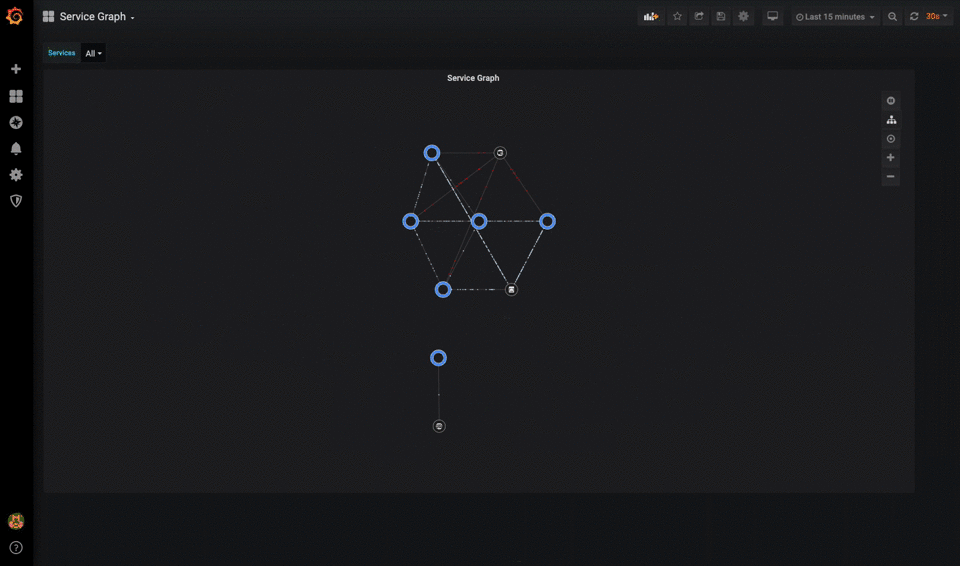
Modern Monitoring Stack
Let's explore the core components of a modern monitoring stack composed by Prometheus and Grafana.
Prometheus: The Metrics Foundation
Prometheus has become the de facto standard for metrics collection in cloud-native environments. Its pull-based architecture and powerful query language make it ideal for monitoring containerized applications and microservices.
Key Features
- Pull-based Architecture: Unlike traditional push-based systems, Prometheus actively scrapes metrics from targets. This approach provides better control over data collection and makes it easier to detect if a target is down.
- Time-series Database: Prometheus stores all data as time series, making it efficient for storing and querying metrics over time. Each time series is uniquely identified by its metric name and key-value pairs called labels.
- PromQL: The Prometheus Query Language (PromQL) allows for complex queries and data manipulation. It supports rates, aggregations, and mathematical operations, making it powerful for analyzing trends and patterns.
- Service Discovery: Prometheus can automatically discover targets to monitor in dynamic environments like Kubernetes, AWS, or Azure, making it well-suited for cloud-native applications.
Grafana: The Visualization Platform
Grafana serves as the visualization layer, turning complex metrics and logs into understandable dashboards and alerts.
Key Features
- Multi-datasource Support: Can combine data from various sources (Prometheus, Loki, SQL databases, etc.) in a single dashboard.
- Rich Visualization Options: Offers various panel types including graphs, heatmaps, tables, and gauges. Each panel type has specific use cases and can be customized extensively.
- Alerting: Provides a unified alerting system that can trigger notifications based on metrics from any data source.
- Dynamic Dashboards: Supports variables and templates, allowing users to create dynamic, reusable dashboards that can filter and display data based on user input.
How These Tools Work Together
The power of this stack comes from how these components complement each other:
- Applications expose metrics endpoints
- Prometheus scrapes these endpoints
- Grafana queries Prometheus and visualizes the data
Deploying a Robust Monitoring Solution
In the following blog post, I go in-depth into building and deploying a robust Monitoring solution with Prometheus and Grafana, adding metrics and alerts to a Golang microservice following all of the best-practices described in this post.
Check it out now and get your hands dirty with monitoring!
Conclusion and Next Steps
Throughout this guide, we've explored the fundamentals of metrics monitoring in the context of Site Reliability Engineering. We've covered:
- The importance of monitoring and its role in maintaining reliable systems
- How to build effective monitoring systems that answer key questions
- The Four Golden Signals as a framework for monitoring
- A modern monitoring stack with Prometheus, Grafana, Loki, and Promtail
Coming Up Next: Service Level Objectives (SLOs)
Next week, we'll explore Service Level Objectives (SLOs), a crucial concept in SRE practices. We'll cover:
- Understanding SLIs, SLOs, and SLAs
- How to define meaningful SLOs
- Setting realistic error budgets
- Implementing SLO monitoring
- Using SLOs to make data-driven decisions
SLOs build naturally on the monitoring foundations we've established today, helping us answer not just "What's broken?" but "Is our service meeting user expectations?"
Subscribe to ensure you don't miss next week's deep dive into Service Level Objectives (SLOs). Your journey to mastering SRE continues! 🎯
If you enjoyed the content and would like to support a fellow engineer with some beers, click the button below :)