

In the past few days, I've been following an online controversy on Twitter involving ShipFast, a popular SaaS boilerplate created by indie hacker Marc Lou. Several security vulnerabilities were found in ShipFast's codebase, including poor data validation, paywall bypass issues, and sensitive company data leaked through public APIs.
In this post, I want to talk about solutions to these issues. I have an opinionated view that security must come first, specially when it means not getting paid, leaking sensitive data to competitors, and allowing users to impersonate whoever they want. All of these issues can have serious implications on your business, including legal implications, and in my honest opinion I don't think its something that should be taken lightly.
This will be a thorough post, intended for engineers who'd like to step up their security practices and better protect their business and customers' data. You may argue that some practices are not necessary for a new software that barely has any users, and while I politely disagree, I'll kindly ask you to still read this post, and then to think carefully about the trade-offs between "The effort of implementing a security solution vs. Dealing with the outcomes of a security breach".
With all of that said, let's get started. I'll talk about a couple of distinct areas that, if implemented properly, could have prevented the issues raised about ShipFast, and that I think are mandatory for services running in production environments.
Authentication & Authorization
Let me start by sharing a common saying: "Never roll your own authentication/authorization".
There are various solutions in the market that deals with most of the hassle of doing Authentication & Authorization. Here are some of the most common ones:
- Clerk: Freemium. 99.99% uptime for Enterprise. Very popular amongst the React community.
- Auth0: Paid. 99.99% uptime for Enterprise.
- Keycloak: Free, Open-Source. You'll have to host and manage it.
With that said, while these platforms certainly help with managing users and securing their credentials and personal information, they don't guarantee the full security of your application. You still need to deal with defining proper access rules (e.g. can a free user access this page? can a non-admin perform this action?), and validating that the user who's making the request is not impersonating anyone else.
With proper authentication and authorization mechanisms in place, ShipFast could have avoided leaking sensitive data and users bypassing their paywall, where the underlying issue seemed to be due to user impersonations not being properly handled.
Auth Tokens
Authentication tokens are the backbone of modern web authentication. Think of them as digital wristbands you get at a festival - they prove you've already been checked at the entrance, so you don't need to show your ID every time you move between stages. They may also grant you special access to certain areas.
Why Do We Need Tokens?
The challenge comes from HTTP's stateless nature: each request to your server is independent, with no inherent way to remember who the user is. So we need a solution that will:
- Avoid sending username/password with every request
- Allow servers to verify users without hitting the database every time
- Work seamlessly across different domains and services
- Scale well in distributed systems
Common Types of Tokens
JSON Web Tokens (JWT)
The de facto standard in modern web applications, JWTs are like sealed envelopes with tamper-evident tape. They're self-contained packages carrying user information within three parts: a header (metadata), payload (user data), and signature (security seal). Their main advantage is the ability to verify without database lookups, making them perfect for distributed systems. Once issued, a token cannot be revoked before expiration. This is why JWTs are typically short-lived, lasting from minutes to a few hours.
Refresh Tokens
Think of refresh tokens as your gym membership card that needs periodic reactivation. When a short-lived JWT expires, rather than forcing a new login, applications use refresh tokens to obtain new JWTs.
This pattern solves the challenge of balancing security with user convenience: you get the security benefits of short-lived JWTs while keeping users logged in for extended periods.
Session Tokens
Unlike JWTs, session tokens are simple random strings stored in a database – like coat check tickets, meaningless without their matching database entry. While this requires a database lookup for every request, it provides immediate control over user sessions. Need to log someone out instantly? Just remove their session token. This makes them ideal for applications requiring fine-grained session control and immediate invalidation capabilities.
A Token's Lifecycle
- Authentication Flow
- User logs in with credentials
- Server verifies and issues tokens
- Server provides an access token (short-lived) and refresh token (long-lived)
- Usage
- Access token is sent with each request (usually as a
Authorizationheader) - Server validates token signature, issuer, and expiration
- If valid, grants access to requested resources
- Access token is sent with each request (usually as a
- Renewal
- Access token expires (typically 15min - 1hr)
- Client uses refresh token to get new access token
- Refresh tokens eventually expire too (days/weeks), requiring re-login
Best Practices with Tokens
- ✅ Always validate tokens properly. Tokens should be signed, and their signatures validated.
- ✅ Always use HTTPS for every authentication & authorization flow.
- ✅ Use short expiration times for access tokens
- ✅ Implement token rotation for sensitive operations
- ✅ Do monitor for suspicious usage of auth services and APIs (e.g. impersonation attempts, failed login attempts, ...)
- ❌ On front-end applications, never store tokens in
localStorageorsessionStorage. Use cookies instead. - ❌ Never store sensitive data in token payload
- ℹ️ XSS attacks could expose tokens stored in JavaScript. Read more here.
- ℹ️ Man-in-the-middle attacks if not using HTTPS. Read more here.
- ℹ️ Replay attacks, if session expiration if not properly configured. Read more here.
Role-Based Access Control (RBAC)
It's common for applications to have some requirement for treating different levels of user permissions. Say your application has an admin dashboard with sensitive information about your company - you definitely don't want any non-admin user sniffing this data! Or say your application has different subscription tiers, and you only want to allow premium users to view certain content - you'll be losing money if a free user finds a way to bypass your paywall.
That's where Role-based authorization comes into place. RBAC is built on two major components:
- Each user is assigned a role, like
adminoruser. - Each role has a set of permissions, or things that users with that role can and can’t do. Permissions can be as simple as the ability to view an entire page, or as complex as editing a specific column in a database table.
For each resource of your application that you want to restrict access to, you need to add what’s called a “check” – some code that makes sure that the currently authenticated user has the required role that allows them to access that resource. How and where you'll implement this code depends on the technologies you use and on the maturity of your infrastructure.
I'll try to highlight some simple strategies for performing role checks. Note that this operation is highly dependent on the technologies you're using to build your application.
- For TypeScript/JavaScript applications secured with Clerk, it's as simple as configuring a middleware (see more details here).
// Function to check if authenticated user has a given `role`
export const checkRole = async (role: Roles) => {
const { sessionClaims } = await auth()
return sessionClaims?.metadata.role === role
}
// Add a middleware to check if user has required roles for accessing /admin pages
const isAdminRoute = createRouteMatcher(['/admin(.*)'])
export default clerkMiddleware(async (auth, req) => {
// Protect all routes starting with `/admin`, redirecting non-admin users to the application's root path `/`
if (isAdminRoute(req) && !(checkRole('admin')) {
const url = new URL('/', req.url)
return NextResponse.redirect(url)
}
})- For a Quarkus and Java back-end microservice its as simple as configuring your application with the auth service, and securing each API endpoint with a
@RolesAllowedannotation.
@GET
@Path("/premium-content")
@RolesAllowed({ "premium" })
@Produces(MediaType.APPLICATION_JSON)
public String getPremiumContent() {
return premiumService.getContent();
}Most frameworks should have authentication libraries that deal with JWTs and RBAC. Do some research, find a well-maintained project, and use that. The concepts should remain the same regardless of the technology: Validate the incoming token, read roles and permissions data, and decide on whether or not to allow the user to perform the requested action.
Preventing User Impersonation
User impersonation occurs when malicious actors attempt to perform actions on behalf of other users. Preventing user impersonation is extremely important to properly secure your applications, and most importantly yours and your users' data.
RBAC helps you with managing which groups of users can access which resources. But if a user is able to impersonate another, even though they might not have an admin role or special permissions, there's still a high security risk in a malicious user fetching sensitive data about another user of your application, and/or performing abusive actions on behalf of them.
Core Concepts
JWT Claims - Important Metadata to validate!
- The
sub(subject) claim uniquely identifies the user. You should use this field to inform you of which user is making the request.- If anywhere in that request the user has to input its own user identifier, always make sure to compare the
subvalue with the user's input, preventing them from performing actions on behalf of other users. - For example, let's build a request to create a new friendship relation between two users. We have two approaches: (1) we can have an API for
POST /friends/<new-friend-id>, and we infer one side of this relation from thesubfield and the other from the request's path parameter<new-friend-id>, or (2) we can have an API forPOST /<user-id>/friends/<new-friend-id>, where we must first check if<user-id>matchessubbefore allowing the request to go through.
- If anywhere in that request the user has to input its own user identifier, always make sure to compare the
iss(issuer) verifies token origin, that is, the authorization service that processed the authentication request for this user.exp(expiration) prevents token reuse- Custom claims can carry additional user context as seen in the RBAC section above (roles, permissions)
Implementation Examples
Let's look at some implementation examples on preventing user impersonation within your APIs.
1. TypeScript + Clerk
import { clerkClient } from '@clerk/clerk-sdk-node';
import { Request, Response, NextFunction } from 'express';
const validateUserAccess = async (req: Request, res: Response, next: NextFunction) => {
try {
// Clerk handles JWT validation automatically
const authUserId = req.auth.userId;
const requestUserId = req.params.userId;
// Prevent impersonation by validating resource ownership
if (authUserId !== requestUserId) {
return res.status(403).send('Forbidden');
}
next();
} catch (error) {
...
}
};
2. Java + Quarkus
@Path("/api/resources")
public class ResourceService {
@Inject
SecurityIdentity securityIdentity;
@POST
@Path("/{userId}/friends/{newFriendId}")
public Response getResource(@PathParam("userId") String userId, @PathParam("newFriendId") String newFriendId) {
// JWT validation handled by Quarkus OIDC
String authUserId = securityIdentity.getPrincipal().getName();
// Validate resource access
if (!authUserId.equals(userId)) {
return Response.status(Response.Status.FORBIDDEN).build();
}
return Response.ok(fetchResource(resourceId)).build();
}
}
Token Validation
As the name suggest, JWTs, short for JSON Web Tokens, are simply JSON objects (encoded in Base64 format). Malicious users could try to create a fake token, forcing roles and permissions from premium or admin users and use that to try and gain unrestricted access to your application.
To avoid this, your application must properly validate each request's authorization token, making sure that it has a valid signature, and that it was generated from trusted sources (check the iss claim). For third-party solutions such as Clerk this is usually performed under the hood and you shouldn't have to worry about it, but always check if that's the case!
Security Checklist for your Auth Implementation
Even though you might be using third-party auth providers, ensure you:
- ✅ Implement proper role-based access control (RBAC)
- ✅ Validate resource ownership before every operation
- ✅ Handle tokens refresh and expiration gracefully (if applicable, for example Clerk deals with this logic for you under the hood).
- ✅ Verify subscription status before accessing premium features
- ✅ Log and monitor authentication events
- ✅ Handle account deletion and data cleanup properly (This is a must for GDPR)
- ✅ Implement proper session timeouts
- ❌ Don't expose validation details
Input Validation
Input validation is your application's immune system. Every piece of data from the outside world is potentially malicious, and treating it as such is fundamental to security. While it might be tempting to trust data coming from your own frontend applications, remember that attackers can craft requests directly to your API endpoints, bypassing any client-side validation.
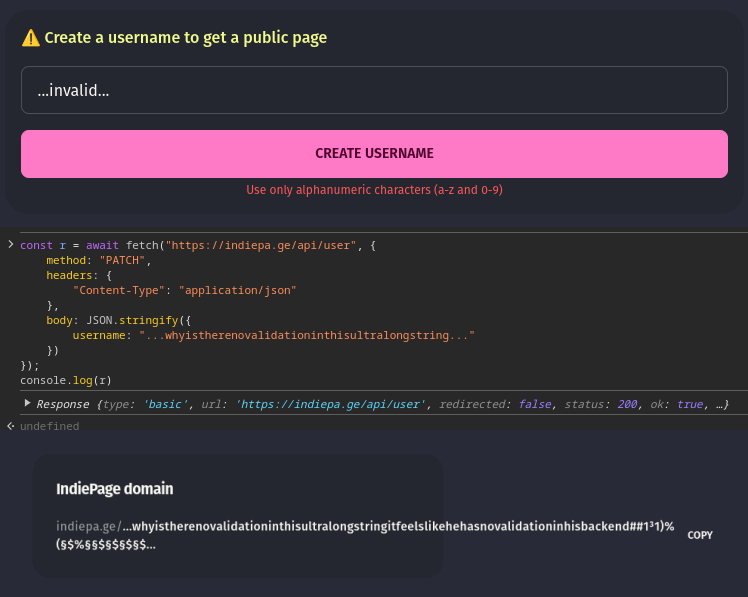
The Three Layers of Validation
Input validation should occur at multiple levels, each serving a distinct purpose:
1. Client-Side Validation (UX Layer)
This is about user experience, not security. Client-side validation helps users quickly understand what they're doing wrong and how to fix it, but it should never be your only line of defense. Think of it as a friendly doorman who checks if you're wearing appropriate attire before letting you wait in line – helpful, but not the actual security check.
For example, let's take this fictional "Tweet" creation form example, using TypeScript and zod as our form schema and validation library.
const TweetSchema = z.object({
content: z.string()
.min(1, "Tweet cannot be empty")
.max(280, "Tweet too long")
.transform(str => str.trim()),
mediaUrls: z.array(z.string().url())
.max(4, "Maximum 4 media items allowed")
.optional(),
replyToId: z.string().uuid().optional()
.refine(async (id) => {
if (!id) return true;
return await tweetExists(id);
}, "Reply tweet doesn't exist"),
visibility: z.enum(["public", "private"])
});
// Usage in API route
const createTweet = async (req: Request, res: Response) => {
const result = await TweetSchema.safeParseAsync(req.body);
if (!result.success) {
return res.status(400).json({ errors: result.error.flatten() });
}
// Safe to use validated data
};2. API Layer Validation (Security Layer)
This is your bouncer – strict, consistent, and trust-nothing. Every input must be validated here, regardless of what the client claims to have checked. This layer protects your application's integrity and prevents malicious data from entering your system.
Let's take the following fictional endpoint for creating a "Tweet", implemented in Golang:
type Tweet struct {
Content string `json:"content" validate:"required,min=1,max=280"`
MediaURLs []string `json:"mediaUrls" validate:"dive,url,max=4"`
ReplyToID *string `json:"replyToId" validate:"omitempty,uuid"`
IsPrivate bool `json:"isPrivate"`
}
func validateTweet(tweet *Tweet) error {
validate := validator.New()
// Custom validation
validate.RegisterValidation("content_not_empty", func(fl validator.FieldLevel) bool {
return strings.TrimSpace(fl.Field().String()) != ""
})
// Async validations
if tweet.ReplyToID != nil {
exists, err := tweetExists(*tweet.ReplyToID)
if err != nil || !exists {
return errors.New("invalid reply_to_id")
}
}
return validate.Struct(tweet)
}3. Database Layer Validation (Data Integrity Layer)
Your last line of defense. Constraints, relations, and data types at the database level ensure that even if something slips through, your data remains consistent and valid. Think of it as the vault's own security system – even if someone gets past the guards, the vault itself remains secure.
For example, take the following fictional "Tweets" table and notice its constraints:
CREATE TABLE tweets (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
user_id UUID NOT NULL REFERENCES users(id) ON DELETE CASCADE, -- Tweet must have a user. If user deletes its account, tweet is automatically removed.
content VARCHAR(280) NOT NULL, -- Enforces max length to 280 characters
reply_to_id UUID REFERENCES tweets(id),
is_private BOOLEAN NOT NULL DEFAULT false, -- Requires a non-null value, defaulting to `false` if none is set.
media_urls TEXT[] CHECK (array_length(media_urls, 1) <= 4), -- Enforces a max limit of 4 media attachments per Tweet
created_at TIMESTAMP WITH TIME ZONE NOT NULL DEFAULT NOW(),
edited_at TIMESTAMP WITH TIME ZONE,
-- Business rules as constraints
CHECK (edited_at IS NULL OR edited_at > created_at),
CHECK (reply_to_id IS NULL OR reply_to_id != id) -- Can't reply to itself
);Common Pitfalls and Their Solutions
Instead of simply listing what not to do, let's understand why certain practices are problematic and how to address them properly:
Trusting Client-Side Validation
Consider an image upload feature. Your front-end validates the attached file's size and type, but an malicious user can easily bypass this. Always implement robust server-side validation that:
- Verifies file content matches claimed extension
- Scans for malicious content
- Enforces size limits
- Validates file metadata
Inconsistent Validation
Imagine a username field that's validated differently across your system:
// Don't have different rules in different places
frontend: /^[a-z0-9]{3,16}$/
backend: /^[a-zA-Z0-9]{4,20}$/
database: VARCHAR(32)
Instead, you must maintain consistent validation rules across your systems. Whenever possible, have a single source of truth for your validation rules.
Real-World Validation Checklist
When implementing input validation, consider these comprehensive checks:
- Syntax Validation: Beyond basic type checking, ensure the data makes sense in context. For example, when validating a date of birth:
- Check it's a valid date format
- Ensure it's in the past
- Verify it's within reasonable bounds (e.g., user should be at least 13 y/o and not older than 150 y/o)
- Semantic Validation: Ensure the data not only has the right format but makes logical sense. For instance, when validating a request to create an invite to a private GitHub Repo:
- Ensure the GitHub username is valid and not assigned to other users
- Check if the user has a valid purchase for accessing getting the invite
Protecting Sensitive Data
ShipFast was exposing Stripe revenue data and user metrics through public API endpoints. This serves as a reminder that data privacy isn't just about user passwords and personal information, but also extends to all sensitive business and operational data.
Access Control Patterns
When designing API endpoints, consider these access patterns:
1. Role-Based Access Control (RBAC)
As previously mentioned, RBAC is a must-have solution for managing access to your application's resources based on different roles and permissions.
2. Resource-Based Access Control
Apart from RBAC, every piece of data should have clear ownership and access rules:
- Owner-Only Data: Such as personal API keys, billing details, and business metrics should only be accessible by the resource owner
- Shared Data: Such as team or organization resources. Must check for valid a team/organization membership.
- Public Data: Should be explicitly marked as public.
Best Practices for Handling Sensitive Data
- Data Classification
- Explicitly classify different levels of data sensitivity in your architecture
- Document which endpoints return sensitive data
- Conduct regular audits of data exposure points
- Principle of Least Privilege
- Users should only see what they absolutely need
- Admins should have scoped access based on their role
- Systems should access only required data
- Data Filtering
- Always filter sensitive fields before sending responses. Do not rely on front-end filtering.
- Create specific DTOs for different access levels
- Audit Trail
- Log access to sensitive data
- Track changes to permission levels
- Monitor unusual access patterns
Common Pitfalls
1. Assuming "Private" APIs are Secure
Just because an endpoint isn't documented or linked in your UI doesn't mean it's secure. All endpoints need proper authentication and authorization.
2. Oversharing in API Responses
// ❌ Dangerous: Oversharing data
const getCompanyInfo = async (companyId) => {
const company = await db.company.findOne(companyId);
return company; // Might include sensitive fields (e.g. revenue data)!
}
// ✅ Safe: Explicit field selection
const getCompanyInfo = async (companyId) => {
const user = await db.users.findOne(companyId, {
select: ['id', 'name', 'logo_url']
});
return user;
}
Security Checklist for Sensitive Data
Before deploying any API endpoint, verify:
- ✅ Data Classification: Have you properly classified the sensitivity of all data being exposed?
- ✅ Access Control: Are there explicit checks for user permissions and data ownership?
- ✅ Data Filtering: Are you explicitly selecting only the necessary fields rather than returning entire objects?
- ✅ Audit Capability: If dealing with sensitive data, can you track who accessed what data and when?
- ✅ Error Handling: Do error messages avoid leaking sensitive information?
Securing Webhook Endpoints
Webhooks are crucial for event-driven architectures, but they're open, public endpoints that accept incoming data – making them potential security vulnerabilities. There were a few reports on ShipFast's codebase not securing its webhook endpoints, which can lead to huge implications depending on what kind of service is emitting those webhook events. Imagine not securing Stripe webhooks. Malicious users could easily trick your service into thinking they performed a valid purchase!
With that said, let's explore some strategies on how to implement them securely.
Signature Verification
The most critical security measure for webhooks is verifying that the incoming request truly comes from your trusted sender. Most major services (Stripe, GitHub, Slack) use HMAC signatures for this purpose.
// Simple HMAC verification
const isValidStripeWebhook = (payload: string, signature: string, secret: string) => {
const hmac = crypto
.createHmac('sha256', secret)
.update(payload)
.digest('hex');
return crypto.timingSafeEqual(
Buffer.from(hmac),
Buffer.from(signature)
);
};
Idempotency
Webhook deliveries may be retried multiple times. Your handler must be idempotent to prevent duplicate processing:
async function handlePaymentWebhook(event) {
// Use event ID as idempotency key
const processed = await redis.get(`webhook:${event.id}`);
if (processed) return;
try {
await processPayment(event);
// Caches the processing of this payment, if successful, in order to avoid duplicate processing.
await redis.set(`webhook:${event.id}`, 'processed', 'EX', 86400);
} catch (error) {
// Clear key if processing failed to allow for retries
await redis.del(`webhook:${event.id}`);
throw error;
}
}
Security Checklist
Essential security measures for webhook endpoints:
- Transport Security: Use HTTPs.
- IP Allowlisting: Consider restricting to known IP ranges or hostnames of your webhook provider
- Request Timeouts: Set appropriate timeouts for both receiving and processing
- Error Handling: Log failures without exposing internal details in responses
Best Practices
Webhook Secret Management
Store webhook secrets securely (never version control them!) and rotate them periodically. Some services support multiple secrets to enable zero-downtime rotation:
const secrets = [
process.env.STRIPE_WEBHOOK_SECRET_CURRENT,
process.env.STRIPE_WEBHOOK_SECRET_PREVIOUS
];
const isValidSignature = (payload, signature) =>
secrets.some(secret => verifySignature(payload, signature, secret));
Version Your Webhook Endpoints
Include the version in your webhook URL to maintain backward compatibility:
https://api.yourapp.com/v1/webhooks/stripe
This allows you to handle payload format changes without breaking existing integrations.
Error Recovery
Design your webhook handlers with failure recovery in mind:
- Consider implementing a dead letter queue for failed events, which enables you to review these events, and retry them.
- Create admin tools to retry failed webhooks
- Set up alerting for repeated failures
Testing Webhook Handlers
Secure webhook handlers should be thoroughly tested. Create test cases for:
- Valid signatures with various payload types
- Invalid signatures
- Duplicate event IDs
- Malformed payloads
- Network timeouts
- Database failures during processing
Many providers offer webhook testing tools (like Stripe's CLI) – use them during development to validate your implementation.
Conclusion
The recent controversy around ShipFast serves as a reminder that security isn't optional – it's fundamental. While the "ship fast" philosophy has its merits, it should never come at the expense of basic security practices. By following these guidelines and implementing proper security measures from the start, you can build fast AND secure applications.
Additional Learning Resources
- Web Security for Developers: Real Threats, Practical Defense
- Web Application Security: Exploitation and Countermeasures for Modern Web Applications
- OWASP Top 10
- OWASP API Security Project
- Node.js Security Checklist
- Express.js Security Best Practices
Subscribe to ensure you don't miss next week's deep dive into monitoring fundamentals. Your journey to mastering SRE continues! 🎯
If you enjoyed the content and would like to support a fellow engineer with some beers, click the button below 😄